Apache spark user memory

PySpark combines Python’s learnability and ease of use with the power of Apache Spark to enable processing and analysis .
Spark’s scheduler is fully thread-safe and supports this use case to enable applications that serve multiple requests (e.Temps de Lecture Estimé: 6 min
Spark Memory Management
It’s crucial to ensure that the executor memory is at least 1. Coursera Introduc2on to Apache Spark, . One first basic approach to memory sizing for Spark jobs, is to start by giving the executors ample amounts of memory, provided your systems has enough resources. queries for multiple users). Google BigQuery , TensorFlow , AWS Athena , and others also use Arrow similarly. The purpose of this config is to set aside memory for internal metadata, user data .Python SparkConf. Installing Apache Spark involves extracting the downloaded file to the desired location. See Also – Limitations Of Apache Spark. We can explicitly specify whether to use replication while caching data by using methods such as DISK_ONLY_2, .March 27, 2024.Deep Dive: Apache Spark™ Memory Management.Always use the apache-spark tag when asking questions; Please also use a secondary tag to specify components so subject matter experts can more easily find them. This in-memory computing capability is one of the key .Spark executor memory overhead refers to additional memory allocated beyond the user-defined executor memory in Apache Spark. Each executor . Table of Contents.Spark configuration docs. The lower this is, the more frequently spills and cached data eviction occur. The Arrow project also defines Flight , a client-server RPC framework to build rich services .
Documentation
Apache Spark Memory Management: Deep Dive
Your total cluster resources are Total cores 32 Total RAM 244 GB.If true, Spark will attempt to use off-heap memory for certain operations. // Example of setting executor memory.This is the memory pool managed by Apache Spark.memory: Amount of memory to use per executor process.Apache Spark is a distributed computing engine. If you have 10 nodes, then specify the number of executors. 2️⃣ User Memory: - Size: (Total .
Job Scheduling
For real time, low latency processing, you may prefer Apache Kafka ⁴. It enables you to perform real-time, large-scale data processing in a distributed environment using Python. The reason for this is that the Worker lives within the driver JVM process .
In-Memory Database
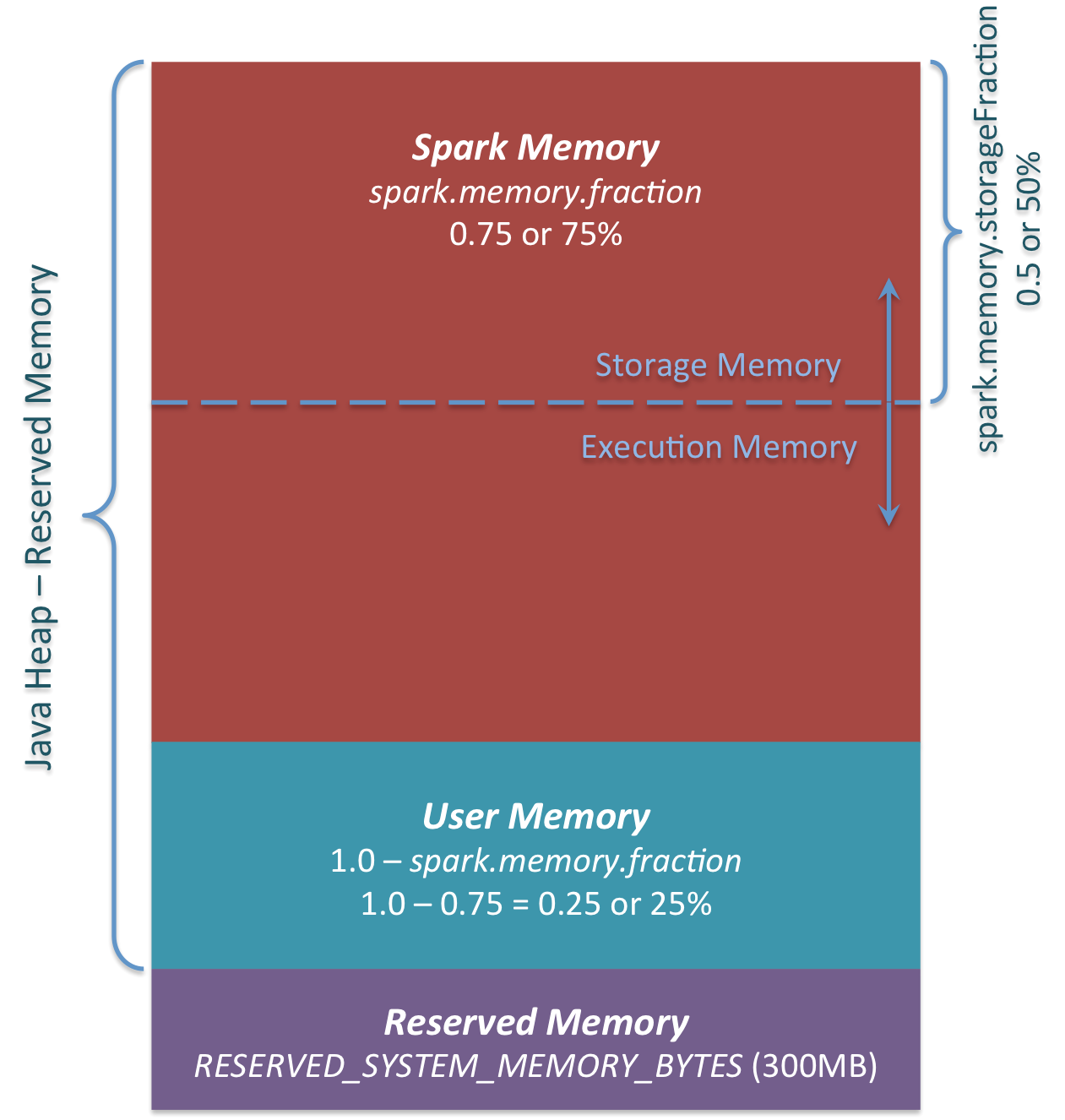
Its size can be calculated as (“Java Heap” – “Reserved Memory”) * spark.You can try either of the below steps: Memory overhead should be 10% of the Executor memory or 328 MB. Hence, it is obvious that memory management plays a very important role in the whole system. It also provides a PySpark shell for interactively analyzing your data.fraction - the .Since you are running Spark in local mode, setting spark.
How to Set Apache Spark Executor Memory
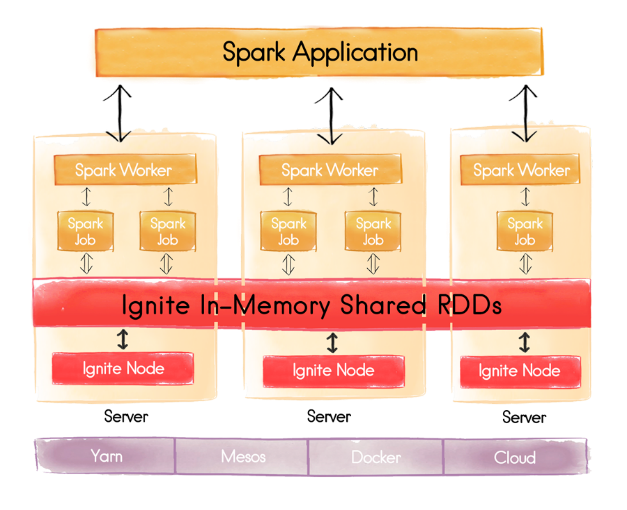
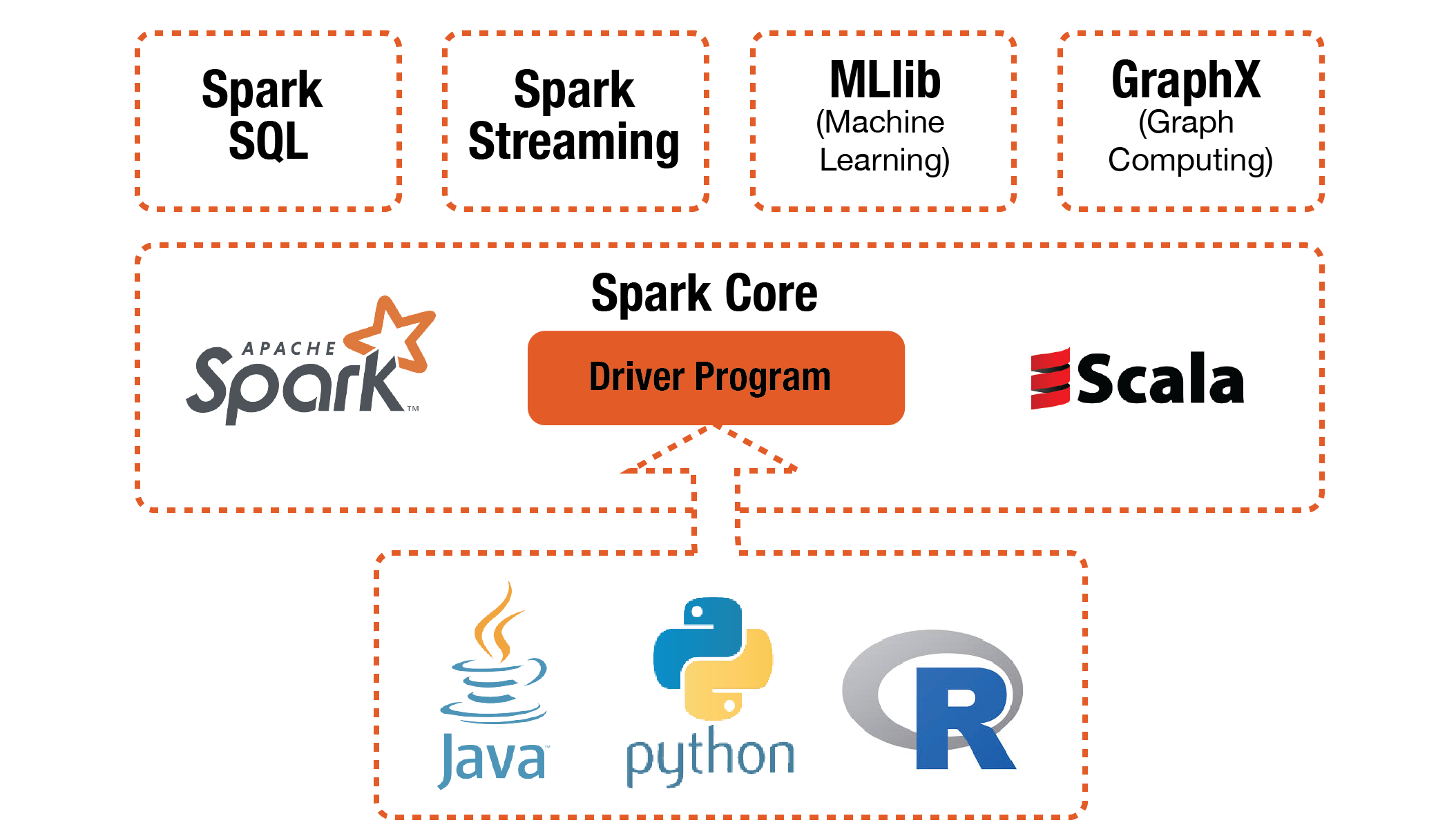
Apache Ignite provides an implementation of the Spark RDD, which allows any data and state to be shared in memory as RDDs across Spark jobs. It is crucial for .Apache Spark addresses these limitations by generalizing the MapReduce computation model, while dramatically improving performance and ease of use. You need to turn to other frameworks like . It can use the standard CPython interpreter, so C libraries like NumPy can be used. Examples include: pyspark, spark-dataframe, spark-streaming, spark-r, spark-mllib, spark-ml, spark-graphx, spark-graphframes, spark-tensorframes, etc. First 1 core and 1 GB .Apache Spark ™ examples. 1000m, 2g (default: total memory minus 1 GiB); note that each . Unified Memory Manager (Unified memory management) 통합. From the configuration docs, you can see the following about spark. Fast and Easy Big Data Processing with Spark At its core, Spark provides a general programming model that enables developers to write application by composing arbitrary operators, .

Broadly speaking, spark Executor JVM memory can be divided into two parts.fraction) Calculation for 4GB : User Memory = (4024MB — 300MB) * .What kind of heavy objects might get stored in user memory that one should be careful of and should take into consideration while deciding to set the necessary .
pyspark
2, columnar encryption is supported for Parquet tables with Apache Parquet 1.py as:
pyspark
size must be positive.memory memory_value.fraction: Fraction of (heap space - 300MB) used for execution and storage.enabled in Spark Doc. With small data sets, it’s not going to give you huge gains, so you’re probably better off with the typical libraries and tools.Apache Spark provides a suite of web user interfaces (UIs) that you can use to monitor the status and resource consumption of your Spark cluster.Formula: User Memory = (Java Heap — Reserved Memory) * (1. Spark’s expansive API, excellent performance, and flexibility make it a good option for many analyses . 정적 메모리 관리자는 유연성 부족으로 인해 더 이상 . This page shows you how to use different Apache Spark APIs with simple examples. It improves the performance and ease of use. If off-heap memory use is enabled, then spark.
Use cases
By default, Spark’s scheduler runs jobs in FIFO fashion.A basic solution.Traitement de données en mémoire : Introduc2on à Spark.
Apache Spark Performance Acceleration
Close-to-real-time: Apache Spark is not designed for true real-time processing as it processes data in micro-batches, with a maximum latency of around 100 milliseconds.1 works with Python 3.conf ): // Syntax.
Configuration
Spark is a great engine for small and large datasets.메모리 관리는 두 가지로 나뉩니다. In the era of Big Data, processing large amounts of data through data-intensive applications, is presenting a challenge.Configuration property details.
Memory Allocation in Apache Spark
As you see, Spark isn’t the best tool for every job, but it’s .MEMORY_ONLY¶ StorageLevel.
The user memory region is allocated for user-defined objects and data structures within Spark applications. It also works with PyPy 7. save , collect) and any tasks that need to run to evaluate that action.Costly infrastructure: Apache Spark uses RAM for its in-memory computations for real-time data processing.SPARK_WORKER_MEMORY: Total amount of memory to allow Spark applications to use on the machine, e.It stores Spark’s internal objects and metadata.0 defaults it gives us (“ Java.Spark is designed as an in-memory data processing engine, which means it primarily uses RAM to store and manipulate data rather than relying on disk storage.Critiques : 3
Apache Spark Memory Management
It is designed to deliver the computational speed, scalability, and programmability required for big data—specifically for streaming data, graph data, analytics, machine learning, large-scale data processing, and artificial . Memory management is at the heart of any data-intensive system.Apache Spark (Spark) easily handles large-scale data sets and is a fast, general-purpose clustering system that is well-suited for PySpark. On-Demand Webinar. Remove Driver Cores.MEMORY_AND_DISK: Persist data in memory and if enough memory is not available evicted blocks will be stored on disk. It is designed to perform both batch processing (similar to . It caches intermediate data into memory, so there is no need to repeat the computation or reload .Apache Ignite as a distributed in-memory database scales horizontally across memory and disk without compromise. It includes memory used by custom libraries, UDFs, .Step 5: Install Apache Spark. It can be used with single-node/localhost environments, or distributed clusters.How does Spark relate to Apache Hadoop? Spark is a fast and general processing engine compatible with Hadoop data.5 * 360MB = 180MB.
Deep Dive: Apache Spark Memory Management
Spark applications in Python can either be run with the bin/spark-submit script which includes Spark at runtime, or by including it in your setup. This is controlled by property spark., spark-defaults.memoryOverhead, spark. Don't increase it to any value. Parquet uses the envelope encryption practice, where file parts are encrypted with “data encryption keys” (DEKs), and the DEKs are encrypted with “master encryption keys” (MEKs).

An in-memory distributed computing system; Apache Spark is often used to speed up big data applications.
Community
PySpark is the Python API for Apache Spark. Static Memory Manager (Static Memory Management) 정적. Please do not .storageFraction * Usable Memory = 0.To calculate reserved memory, user memory, spark memory, storage memory, and execution memory, we will use the following parameters: spark. Apache Ignite works with memory, disk, and Intel Optane as active storage tiers.You can set the executor memory using Spark configuration, this can be done by adding the following line to your Spark configuration file (e.For multi-user systems, with shared memory, Hive may be a better choice ².set Examplespython. Resilient Distributed Datasets, Henggang Cui.size: 0: The absolute amount of memory in bytes which can be used for off-heap allocation.0부터 통합 메모리 관리자가 Spark의 기본 메모리 관리자로 설정되었습니다.This section provides background knowledge about Apache Spark platform, features and cache memory management, to help understand the different techniques . It is not related to the topic but I still remember the concepts of Pool .memory won't have any effect, as you have noticed. Spark memory and User memory. OFF_HEAP: Data is persisted in off-heap memory. Create a new folder named Spark in the . How to Set Apache Spark/PySpark Executor Memory? Spark or PySpark executor is a worker node that runs tasks on a cluster. The Ignite RDD provides a shared, mutable view of the data stored in Ignite caches across different Spark jobs, workers, or applications. The DEKs are randomly generated by Parquet for each encrypted .Apache Spark uses Arrow as a data interchange format, and both PySpark and sparklyr can take advantage of Arrow for significant performance gains when transferring data.fraction, and with Spark 1.