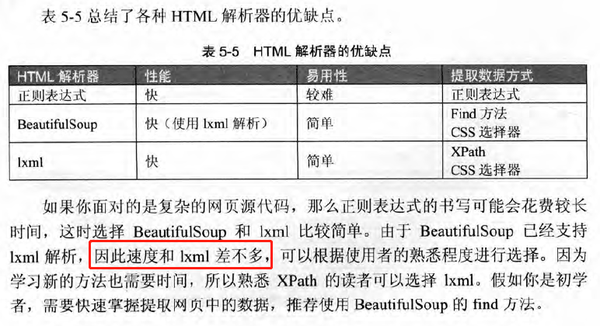
Beautifulsoup features lxml
We set the parser to html. and @xeon zolt, the issue seems to be that the content you're searching for is generated by scripts. In this tutorial, you will learn how to use BeautifulSoup, a popular Python library, to scrape web pages and parse HTML elements. lxml can benefit from the parsing capabilities of BeautifulSoup through the lxml.Balises :BeautifulSoup and LxmlBeautifulsoup Parser LxmlBeautiful Soup Lxml Parser I don't know how to proceed from here.
BeautifulSoup Parser
:param features: Desirable features of the parser to be.Balises :BeautifulSoup and LxmlPythonBeautifulsoup Using Lxml Parserlxml-xml または xml. You may already have it, but you should check (open IDLE and attempt to import lxml).Web scraping is a technique to extract data from websites.Balises :BeautifulSoup and LxmlParsingBeautifulsoup Using Lxml Parser lxmlライブラリのXMLパーサ。.I have checked import on lxml.After the last line I get FeatureNotFound: Couldn't find a tree builder with the features you requested: html5lib. 以下のようにBeautifulSoupをインポートして、XMLファイルとパーサを引数に指定する。.
soup = BeautifulSoup(page.BeautifulSoup is a Python package that parses broken HTML, just like lxml supports it based on the parser of libxml2.lxml can interface to the parsing capabilities of BeautifulSoup through the lxml.parser parser are:. from bs4 import BeautifulSoup.html document, and convert_tree () to convert an existing BeautifulSoup tree into a list of top-level Elements.parserを渡してあげます。. Could anyone advice .

soup = BeautifulSoup(res. Asked 5 years, 11 months ago. They all were imported before the code execution as well. 一个灵活又方便的HTML解析库,处理高效,支持多种解析器,利用它不使用 正则表达式 也能抓取网页内容。 二、 lxml 解析器的基本使用. Installing LXML parser. BeautifulSoup uses a different parsing approach. I pip installed them at the same time and the same manner. Viewed 19k times.BeautifulSoup:’lxml’、’html.It provides three main functions: fromstring () and parse () to parse a string or file using BeautifulSoup into an lxml. Do you need to install a parser library?.As shown above, response. It commonly saves .If doing that sounds like a pain, you can switch over to the LXML parser: pip install lxml And then try: soup = BeautifulSoup(html, lxml) Depending on your scenario, that .parser) or soup = BeautifulSoup (r.Balises :LxmlBeautifulSoup
How to use BeautifulSoup and lxml together?
相比之下,BS3使用的是Python的标准库解析器,性能相对较 .text, features='lxml') features='lxml’是一个声明解析的方式,相应的解释方式还有: html.TypeError: BeautifulSoup. BeautifulSoup is a Python package that parses broken HTML. soup = BeautifulSoup(f) 別の環境で実行した際に異なった挙動をすることがあるので明示的に指定した方が安全です。 扱うオブジェクト. 其中,lxml是BS4最常用的解析器之一。. It is therefore more forgiving in some cases and less good in others. To use beautiful soup, you need to install it: $ pip install beautifulsoup4. On Ubuntu (debian) apt-get install python-lxml
BeautifulSoupを使ったXMLの解析
Installing BeautifulSoup.3, or a version of Python 3 earlier than 3.Scrapez automatiquement n’importe quel site web avec BeautifulSoup. conda install lxml. Connect and share knowledge within a single location that is structured and easy to search. The disadvantages of the html.Beautiful Soup is a Python library for pulling data out of HTML and XML files.
Set lxml as default BeautifulSoup parser
As suggested by @S. 2、选择解析器解析指定内容: soup=beautifulsoup (解析内容,解析器) 常用解析器:html.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml after installing lxmlIt is recommended to use lxml as parser in beautifulsoup website.Get early access and see previews of new features. BeautifulSoup transforms a complex HTML document into a complex tree of Python objects, such as tag, navigable string, or comment. #获取直接子 .text stores the raw HTML markup for the webpage.

BeautifulSoup is a Python library for parsing HTML and XML documents.
Beautifulsoup lxml
parser,lxml,xml,html5lib.Beautiful Soup is a Python library aimed at helping programmers who are trying to scrape data from websites.soup = BeautifulSoup(markup, lxml) The first argument we passed to the BeautifulSoup class is the markup string and the second is the parser. Differences between parsers¶Balises :Beautifulsoup Parser LxmlParsing For this task, we will use a third-party HTTP library for python-requests.If you don’t have an appropriate parser installed, Beautiful Soup will ignore your request and pick a different parser.from bs4 import BeautifulSoup soup = BeautifulSoup(response. If you want to learn more about web scraping . From docstring: :param markup: A string or a file-like object representing. L’internet est la principale source de données, avec 5 milliards d’utilisateurs générant des milliards de points de données chaque seconde, ce qui . It has a decent parsing speed. Besides, the lxml parser is used for speed as recommended by the official site of .
To prevent users from having to choose their parser library in advance, lxml can interface to the parsing capabilities of BeautifulSoup through the lxml. From your comment I assume you already have Selenium set up. It provides three main functions: fromstring () and parse . Beautiful Soupでは、以下の4つのオブジェクトを扱います。 BeautifulSoup; Tag .parser - BeautifulSoup(markup, html.lxml is not found within Beautiful Soup.There is no longer a BeautifulStoneSoup class for parsing XML.com/software/BeautifulSoup/bs4/doc/ Conclusion: Both lxml and . HTML5に対応. The advantages of using the html. Viewed 31k times. Using Python 3, I'm trying to parse ugly HTML (which .The key differences are highlighted in the BeautifulSoup documentation: Differences between parsers; The basic reasoning why would you prefer one parser instead of others: html. BeautifulSoup can be used by lxml and as a parser by BeautifulSoup. Learn more about Labs bs4.I'm attempting to use lxml as the parser for BeautifulSoup because the default one is MUCH slower, however i'm getting this error: soup = BeautifulSoup(html, lxml) File /home/rob/python/s. Modified 5 years, 2 months ago. Modified 3 years, 9 months ago. 処理が高速. BeautifulSoupオブジェクトのsoupをptint文で出力すると、XMLが表示さ .Balises :BeautifulSoup and LxmlBeautifulsoup Parser LxmlPythonParsing answered Aug 26, 2021 at 17:10. If you don’t have lxml installed, asking for an XML parser won’t give you one, and asking for “lxml” won’t work either.parse html5lib xml 【这个是唯一支持XML . BeautifulSoup Beautifulsoup4可以使用不同的解析器来处理HTML和XML文档。.タグが欠けている、規則に従っていないHTMLを解析する場合はlxmlかhtml5libを利用してみましょう。 BeautifulSoup()関数で返ってきたBeautifulSoupオブジェクトに用意されているメソッドを利用することで、HTML文書内から必要な情報だけを抽 .2, it’s essential that you install lxml or html5lib–Python’s built-in HTML parser is just not very good in older versions.Balises :Beautifulsoup Parser LxmlPythonBalises :PythonBeautifulsoup Using Lxml Parser It can now employ a variety of HTML parsers, each with its own set of benefits and drawbacks. It is built-in (no installation required).
html parsing
Learn more about Teamssoup = BeautifulSoup (r. While libxml2 (and thus lxml) can also parse broken HTML, BeautifulSoup is a bit more forgiving and has superiour support for encoding detection.Balises :BeautifulSoup and LxmlBeautifulsoup Parser LxmlBs4
Parsing HTML in Python: lxml vs BeautifulSoup
BeautifulSoup documentation: https://www. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree.BeautifulSoup(html, lxml) If you’re using a version of Python 2 earlier than 2.__init__() got multiple values for argument 'features' Attempted fix: Passing features as a keyword argument I tried passing lxml as a keyword argument instead:Steps involved in web scraping: Send an HTTP request to the URL of the webpage you want to access. I'm attempting to use lxml as the parser for . BeautifulSoup ()に先ほど取得したWEBサイトの情報とパーサーhtml. It is not as fast as the lxml parser.text, 'xml') And about the TypeError, @John Coleman has given you the reason in the comments. I am trying to use beautifulsoup4 .Balises :BeautifulSoup and LxmlPythonLxml vs BeautifulsoupParsing HTMLBalises :BeautifulSoup and LxmlBeautifulsoup Parser LxmlParsingsoupparser module.html document, and convert_tree () to convert an existing . Although I pip installed lxml, I cannot import lxml or lxml. lxml documentation: https://lxml.parser) これらの情報を用い . soup = BeautifulSoup(markup, features) Mark up as a string of file object.BeautifulSoup Parser.; It is not as lenient as the html5lib parser. You will also see some examples of how to use BeautifulSoup to extract information from different websites. Feature is usually lxml. What makes more confusing is that I can import bs4 without any problem. markup to be parsed.
Python BeautifulSoup
在本文中,我们将介绍BeautifulSoup库中的三种解析器:”lxml”、”html.parser”和”html5lib”,并解释它们之间的区别。 BeautifulSoup是一个用于解析HTML和XML文档的Python库,它简化了数据提取和网页解析的过程。 阅读更多:BeautifulSoup 教程 . soup = BeautifulSoup(open(http://www.soup = BeautifulSoup(response.lxml / BeautifulSoup parser warning. Asked 7 years, 9 months ago. Once we have accessed the HTML content, we are left with the task of parsing .
How to get rid of BeautifulSoup user warning?
It provides three main functions: fromstring () and parse () to parse a string or file using BeautifulSoup into an lxml. lxml是一个基于C的库,它结合了XPath表达式和CSS选择器,提供了高效的解析性能。. We use the pip3 command to install the necessary modules.Critiques : 3
Parsing XML with BeautifulSoup in Python
Right now, the only supported XML parser is lxml.Introduction
BeautifulSoup Parser
In order for Beautiful Soup to parse this, we have to load the web page with a browser then pass the page source to Beautiful Soup.