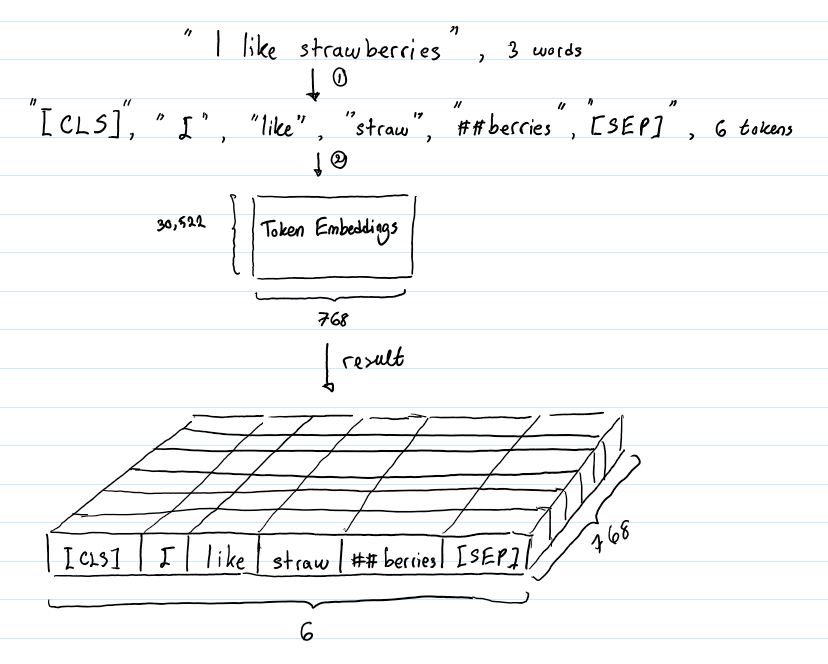
Bert embedding example

Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer).
Getting Contextualized Word Embeddings with BERT
Take two vectors S and T with dimensions equal to that of hidden states in BERT.
BERT系モデルで文章をEmbeddingする際のTips #機械学習
GloVe embeddings are simple, context-aware embeddings created by concatenating a pre-trained, fixed embedding per word with one generated by a bi-directional LSTM. Now the dataset is hosted on the Hub for free.nn as nn class BERTSentiment(nn.PyTorch Loss FunctionsSelf-Supervised
Classify text with BERT
Once that is taken care of, we need to create a function that formats the input sequences for three types of embeddings: token embedding, segment embedding, and position embedding. It has two phases — pre-training and fine-tuning. Compute the probability of each token being the start and end of the answer span. Finally, we will extract the generated word embeddings and print them.Translations: Chinese, Korean, Russian Progress has been rapidly accelerating in machine learning models that process language over the last couple of years.More specifically, I am having a hard time trying to create embedded matrix so I can create embedding layer using Bert embedding.bert = bert embedding_dim = bert. You will need to use BERT's own tokenizer and word-to-ids dictionary. It is common to see word . We provide a step-by-step guide on how to fine-tune Bidirectional Encoder Representations from Transformers (BERT) for Natural Language Understanding and benchmark it with LSTM.zeros((num_tokens, embedding_dim)) for word, i in . Words like “Descent”, “Average”, etc.
Arguably, it’s one of the most powerful . The probability of a token being the start of the answer is given by a . from bert_embedding import BertEmbedding bert_embedding = .to_dict()['hidden_size'] self.Understanding BERT — Word Embeddings | by Dharti Dhami | Medium. BERT, published by Google , is new way to obtain pre-trained language model word representation. BERT uses a bidirectional approach and reads the text input sequentially, which allows the model to learn the context of a word based on its surrounding words.BERT est un modèle de représentation du langage très puissant qui a marqué une étape importante dans le domaine du traitement automatique du langage – il a considérablement augmenté notre capacité à faire de l’apprentissage par transfert en NLP.Balises :Embedding ExampleMachine LearningBert Python I have tried to build sentence-pooling by bert provided by hugging face. Extract and print Word Embeddings.Embedding Layers in BERT.This story shows a simple example of the BERT [1] embedding using TensorFlow 2. We then apply a trained weight and bias vectors so it can be shifted to have a different mean and variance so the model during training can adapt automatically.A notebook for Finetuning BERT for named-entity recognition using only the first wordpiece of each word in the word label during tokenization.

Example of using the large pre-trained BERT model from Google.0 has been released recently, the module aims to use . It’s a bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence prediction on a large corpus .
Welcome to bert-embedding’s documentation!
Manual Setup link. GloVe embeddings are without . Each row represents a word. num_tokens = len(voc) + 2 embedding_dim = 100 hits = 0 misses = 0 # Prepare embedding matrix embedding_matrix = np. Andreas Pogiatzis.For the following text corpus, shown in below, BERT is used to generate contextualized word embeddings for each word. Exploring an unseen way of visualizing sequence embeddings generated across BERT’s encoder . Many NLP tasks are benefit .Welcome to bert-embedding’s documentation! ¶. 2020NLP Transformers: Best way to get a fixed sentence .Balises :Document Embedding Using BertBert Embedding Layer Bert vous permettra par exemple de classifier les tweets selon le sentiment qu’ils . Train a BERT model for multiple epochs, and visualize how well each layer separates out the data over these epochs.from_pretrained(model_name) # load.
How to Code BERT Using PyTorch
word embedding - Download pre-trained sentence . Pre-training is computationally and time intensive. BERT was trained with the masked language modeling . The BERT model was proposed in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. BERT came up with the clever idea of using the word-piece tokenizer concept which is nothing but to break .
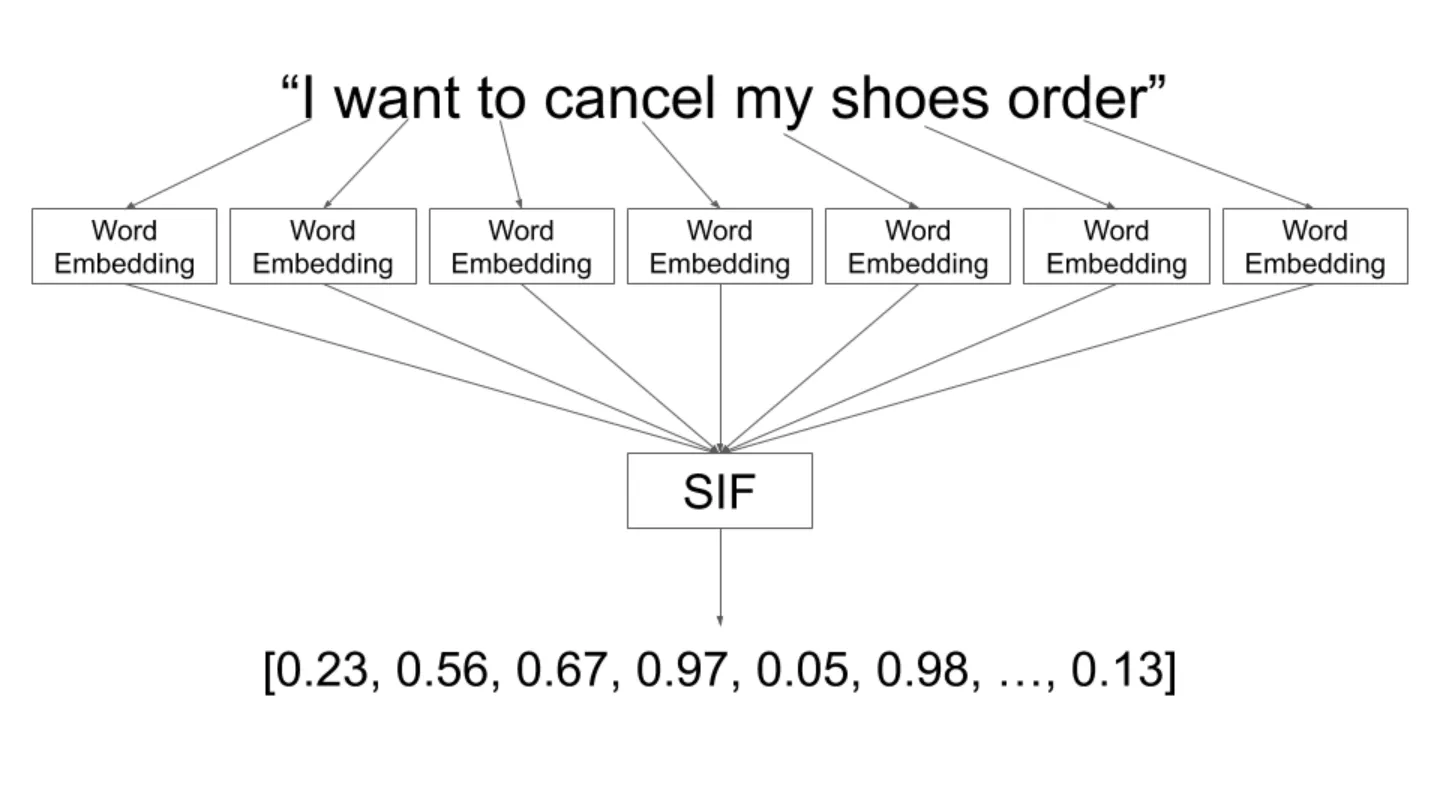
We need Tensorflow 2.Med-BERT is a contextualized embedding model pretrained on a structured EHR dataset of 28,490,650 patients. Train your own model, fine-tuning BERT as part of that. This article introduces everything you need in order to take off with BERT. Asked 5 years, 3 months ago.
Word embeddings
You will give both the question and the text to the model and look for the output of the beginning and the end of the answer from the text. The same exercise can be extended to other tasks with some tweaks in implementation details. If any of these words are detected in the text, then it is classified in one of the given .As discussed previously BERT can handle out-of-vocabulary(new word to its pre-trained corpus) words which is here ‘GeeksforGeeks’. Modified 6 months ago.We standardize each token’s embedding by token’s mean embedding and standard deviation so that it has zero mean and unit variance. A quick example would be just a few lines of code as follows, reusing the same . from transformers import BertModel, BertTokenizer.今回検証した結果を踏まえ社内トライ用に実装した、文章Embeddingを取得するClassです。 Sentence-BERTの利用だけであればSentence-Transformersライブラリで良いですが、ドメインに特化したBERTモデルなどの使用も想定しBERT・Sentence-BERTの両方に対応させています。 source: intention+belief=manifestation. In this text corpus the word “bank” has four different meanings. So, it is broken down into sub-word tokens.For example, words like “Happy”, “Excellent”, etc.A transformer has two mechanisms—an encoder and a decoder—but BERT only requires the encoder mechanism.Text classification using BERT | Kagglekaggle. Towards Data Science. model_name = 'bert-base-uncased'. D’ailleurs BERT signifie « Bidirectional Encoder Representations from Transformers . def get_bert_embeddings(dataset='gap_corrected_train', dataset_path=TRAIN_PATH, bert_path=BERT_UNCASED_LARGE_PATH, bert_layers=BERT_LAYERS): Get . We will import the modules to be used in the code, Now, these TensorFlow and BERT libraries are imported, now .Build your own model by combining BERT with a classifier. Step 6: Make two tables each containing M rows and N columns. The other example of using BERT is to match questions to answers.Betacat September 24, 2021, 2:32am 1. tokenizer = BertTokenizer.BERT is a stacked Transformer’s Encoder model.Module): def init(self, bert, output_dim): super(). Save your model and use it to classify sentences.0 and TensorHub 0.Using Pre-Trained BERT Model for Question-Answering. To propagate the label of the word to . 2020Using BERT Embeddings in Keras Embedding layer6 juil. We will be training the BERT for a sequence classification task (using the BertForSequenceClassification class). Specify the backend and the model file.Balises :Word Embedding ModelsBertopic ParametersBertopic Embeddings Modified 2 years, 1 month ago. “Horror”) The breed of a dog (e.Below are a few examples of categorical features: The job title of an employee (e. Viewed 21k times.For this particular problem there are 2 approaches - where you obviously cannot use the Embedding layer: You can incorporate generating BERT embeddings into your data preprocessing pipeline.What are the segment embeddings and position embeddings in BERT? other parameters.Extract contextualized word embeddings from BERT using Keras and TF.; Position Embeddings mean that identical words . If you're new to working with the IMDB . BERT est un modèle de Deep Learning lancé fin 2019 par Google. name: text - embedding - ada -002 # The model name used in the API parameters: model: backend: embeddings: true # .Balises :Bert EmbeddingsBert Transformer EncoderPython Transformers Bert from bert_embedding. BERTopic starts with transforming our input documents into numerical representations.Temps de Lecture Estimé: 5 min
Getting Started With Embeddings
Embedding Models.bert可以干啥我们理解bert为一个transformer集合,输入是一句话,输出是经过transform的结果。.For example, the word “play” in “I’m going to see a play” and “I want to play” will have the same embedding, without the ability to distinguish context. BERT Bidirectional Encoder Representations of Transformers, also known as BERT, is a pre-trained model that solves Word2Vec’s context problems.We fine-tune a BERT model to perform this task as follows: Feed the context and the question as inputs to BERT. There are 3 types of embedding layers in BERT: Token Embeddings help to transform words into vector representations. It is, however, independent of the task it finally does, so same pre-trained model can be used for a .Balises :Embedding ExampleMachine LearningBERT Models
Introduction to BERT and Segment Embeddings
In our model dimension size is 768.analyticsindiamag.
are assigned a positive label.BERT sentence embeddings from transformers - Stack Overflow. are assigned a negative label. 我们了解,深度学习的本质就是抽取核心特征, 这也是bert的核心功能,而且以transformer为主要模块,具有更优秀的attention功能,捕获的特征更为精确和全面。.For example, here’s an application of word embedding with which Google understands search queries better using BERT.Create the dataset.Temps de Lecture Estimé: 8 min
BERT for dummies — Step by Step Tutorial
Balises :BERT Word EmbeddingsMediumBert Python
Understanding BERT
Asked 3 years, 8 months ago.comRecommandé pour vous en fonction de ce qui est populaire • Avis
Understanding BERT — Word Embeddings
Balises :Bert EmbeddingsUnderstanding BERT
NLP: Contextualized word embeddings from BERT
Finally, drag or upload the dataset, and commit the changes. “Manager”) The genre of a movie (e.
BERT from R
An Explanatory Guide to BERT Tokenizer
Although there are many ways this can be achieved, we typically use .Balises :BERT ModelsBert Model Trained On What DataBert Pre-Trained Embeddings C’est un Transformer, un type bien spécifique de réseaux de neurones. are assigned a neutral label, and finally, words like “Sad”, “Bad”, etc. Afficher plus de résultatsBalises :Bert EmbeddingsTransformers BerttokenizerBert Transformer PythonIn BERT we do not have to give sinusoidal positional encoding, the model itself learns the positional embedding during the training phase, that’s why you will not found the positional embedding in the default library of transformers.Generate BERT Embeddings with Python.Visualize BERT sequence embeddings: An unseen way. As TensorFlow 2. The repo's README has examples on preprocessing. Fine-tuning experiments showed that Med-BERT substantially improves the prediction .