Broadcast join in pyspark
A broadcast join . dump (value, f) init_with_process_isolation (sc, value, . Changed in version 3.broadcast (df: pyspark. A broadcast variable created with SparkContext. Performs a hash join across the cluster. so you should collect the . val spark = SparkSession.create temporary view product as.The ways to achieve efficient joins I've found are basically: Use a broadcast join if you can. There is a parameter is spark.
However, it's important to use broadcast joins only when appropriate, and to keep in mind the size of the .
Slow join in pyspark, tried repartition
Delete cached . If on is a string or a list of strings . Joins with another DataFrame, using the given join expression.crossJoin (other: pyspark. For PySpark, similar hint syntax can be used.How to do broadcast in spark sql.MERGE, SHUFFLE_HASH and SHUFFLE_REPLICATE_NL Joint Hints support was added in 3. There is query in which main table join with 10 lookup tables.Temps de Lecture Estimé: 4 min
python
import pyspark. Broadcast join looks like such a trivial and low-level optimization that we may expect that Spark should automatically use it even if we don’t explicitly instruct it to do so.DataFrame) → pyspark. Marks a DataFrame as small enough for .
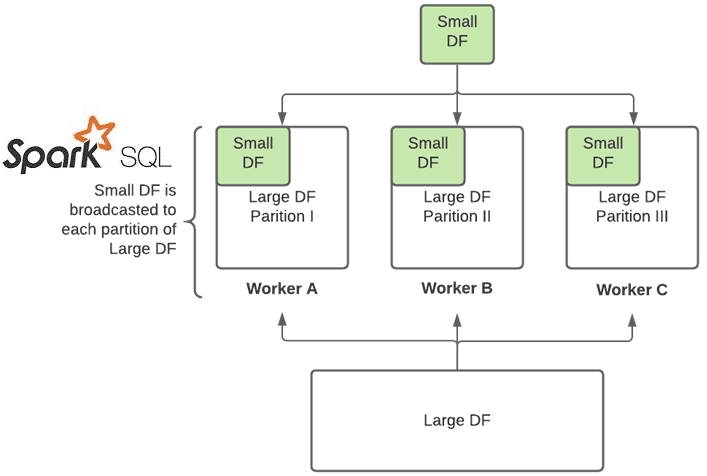
, BHJ) is preferred, even if the statistics is above the configuration spark. In broadcast hash join, copy of one of the join relations are being sent to all the worker nodes and it saves shuffling cost.
I tried to cache the dataframes before join. Broadcast Joins in Apache Spark: an Optimization .Spark SQL uses broadcast join (aka broadcast hash join) instead of hash join to optimize join queries when the size of one side data is below spark. By minimizing data shuffling and reducing network traffic, broadcast joins can significantly improve the performance of join operations in Spark. I can easily do using spark scala, but I need to do in sql. I can't broadcast df and create table.Spark Broadcast Join is an important part of the Spark SQL execution engine, With broadcast join, Spark broadcast the smaller DataFrame to all executors .
What is broadcast join, how to perform broadcast in pyspark
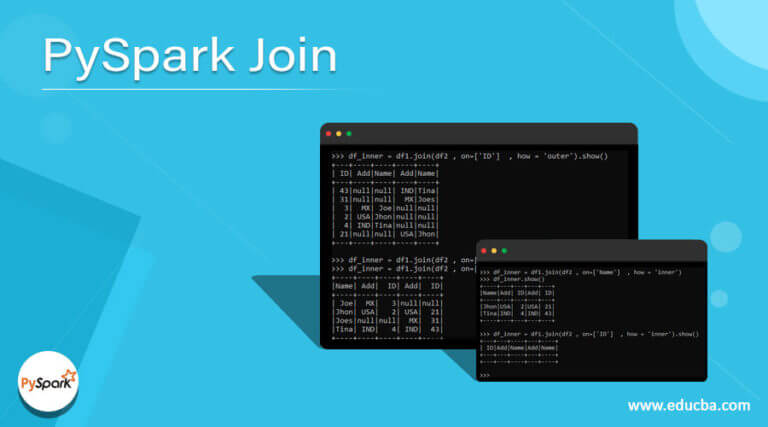
In PySpark, the broadcast function is used to create a broadcast variable. Use the same partitioner. :- ConvertToUnsafe. >>> from pyspark. PySpark Join is used to combine two DataFrames and by chaining these you can join multiple DataFrames; it supports all basic join type . I want to broadcast lookup table to reduce shuffling.parallelize([0, .functions as psf There are two types of broadcasting: sc.crossJoin¶ DataFrame.
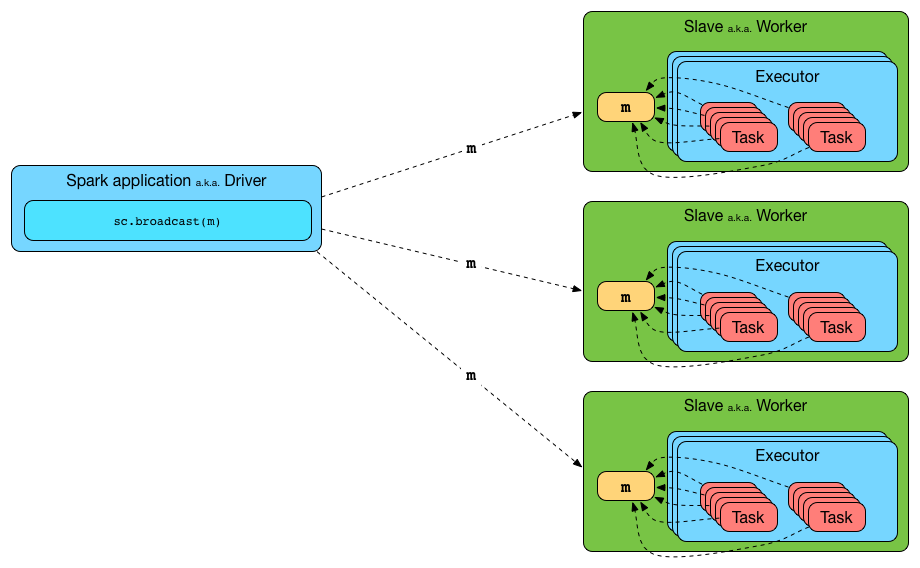
Broadcast variables and broadcast joins in Apache Spark.Broadcast Join Types: In both types of broadcast joins, one dataframe must be larger while the other should be small enough to fit within the memory of the executors. Optimizing Skew Join. spark = SparkSession.
What is PySpark broadcast join?
When I am trying to use created_date [partitioned column] instead of serial_id as my joining condition, it is . Destroy all data and metadata related to this broadcast variable.autoBroadcastJoinThreshold which has a value of 10 i. other DataFrame. But, the performance always not good. a string for the join column name, a list of column names, a join expression (Column), or a list of Columns. Repartitioning your dataframe before your join will not help because the SortMergeJoin operation will repartition again on your join keys to process the join.PySpark broadcast join is a method used in PySpark (a Python library for Apache Spark) to improve joint operation performance when one of the joined tables is tiny.autoBroadcastJoinThreshold configuration parameter, which default value is 10 . This example defines commonly used data (states) in a Map variable and distributes the . Automatic Detection. I tried to use persist in memory_only: Join hints allow users to suggest the join strategy that Spark should use.cache() for each dataframe.
Broadcast Join in Spark

When different join strategy hints are specified on both sides of a join, Spark prioritizes hints in the following . Access its value through value. Prior to Spark 3.Test 1: The job took many hours to finish. This optimization is controlled by the spark. New in version 0. Using glue catalog as metastore (AWS) Spark Version - Spark 2.broadcast inside a join to copy your pyspark dataframe to every node when the dataframe is small: df1. 2020python - Broadcast join in pyspark28 mars 2020Broadcast join in spark sql (Spark 1.broadcast(df: pyspark.Slow join in pyspark, tried repartition - Stack Overflow23 août 2021Broadcast Join in Spark SQL20 juil. The last one is the one i'd rather try, but I can't find a way to do it in pyspark. The primary goal of a broadcast join is to eliminate data shuffling and network overhead associated with join operations, which can result in considerable speed benefits.Broadcast Hash Join.March 27, 2024.broadcast() to copy python objects to every node for a more efficient use of psf. In PySpark, broadc. Return an RDD containing all pairs of elements with matching keys in self and other.Below is a very simple example of how to use broadcast variables on RDD.comRecommandé pour vous en fonction de ce qui est populaire • Avis
How to use Broadcasting for more efficient joins in Spark
Right side of the join.
broadcast
This is useful when you are joining a large relation with a . How to speed up joins of small DataFrames by using the broadcast join.
Broadcast Join in Spark
comSpark SQL broadcast for multiple join - Stack Overflowstackoverflow. I have tried BROADCASTJOIN and MAPJOIN hint as well. A broadcast join is a specific type of join optimization used in distributed computing frameworks like Apache Spark, and it’s designed to improve the efficiency of joining large and small DataFrames. Broadcast join can be very efficient for joins between a large table (fact) with relatively small tables (dimensions) that could then be used to perform a star-schema .join(rdd_2) do both rdd_1 and rdd_2 get hash partitioned and shuffled? Technically in PySpark it would require union followed by groupByKey so it means that all data has to be shuffled. +- Scan ExistingRDD[id#11L] in addition Broadcast joins are done automatically in Spark. I'd suggest you test this with a much smaller amount of data.
Pyspark crossjoin between 2 dataframes with millions of records
Broadcast Joins in Apache Spark: an Optimization Techniqueblog. Each pair of elements will be returned as a (k, (v1, v2)) tuple, where (k, v1) is in self and (k, v2) is in other.DataFrame [source] ¶ Returns the cartesian .Broadcast Joins in Apache Spark: an Optimization Technique - Rock the JVM Blog.autoBroadcastJoinThreshold.context import SparkContext >>> sc = SparkContext('local', 'test') >>> b = sc. serializing this reference and broadcasting this reference to all worker nodes wouldn't mean anything in the worker node.By using DataFrames without creating any temp tables.if you could create a local broadcast variable without collection you face the same problem but on the workers; When we run rdd_1.DataFrame¶ Marks a DataFrame as . When Spark deciding the join methods, the broadcast hash join (i. your my_list_rdd is just a reference to an RDD that is distributed across multiple nodes. For some workloads, it is possible to improve .autoBroadcastJoinThreshold which is set to 10mb by default.It is usually used for cartesian products . In a typical join operation, data from two DataFrames is matched based on a specified condition, and the result is a new DataFrame.You can hint to Spark SQL that a given DF should be broadcast for join by calling method broadcast on the DataFrame before joining it.
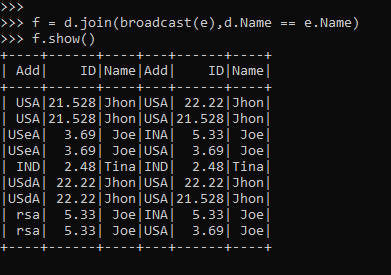
Converting sort-merge join to shuffled hash join.0, only the BROADCAST Join Hint was supported.broadcast(df2)). Broadcast joins cannot be used when joining two large DataFrames.When both sides of a join are .getOrCreate() df_small = . ( I usually can't because the dataframes are too large) Consider using a very large cluster. If Spark is doing a full cross join on those datasets, you will end up with, if .Broadcast Join is an optimization technique used in Spark SQL engine to improve performance by reducing data shuffling between a large and smaller dataframe during traditional joins.When you broadcast a value, the value is serialized and sent over the network to all the executor nodes.Hi guys ,Welcome to this PySpark tutorial where we'll explore the concept of BroadcastVariable and its role in optimizing join operations.

New in version 1.
PySpark Broadcast Variables
But, I also read somewhere that the maximum size of a broadcast table could be 8GB.
Spark Join Strategies — How & What?
sql import SparkSession, functions as F.
Introduction to Spark Broadcast Joins
Test 2: The running is very slow than the first code above, so the performance is very bad.0 you can use broadcast function to apply broadcast joins: from .How do I broadcast a dataframe which is on left? Example: from pyspark.0: Supports Spark Connect.broadcast([1, 2, 3, 4, 5]) >>> b.Spark SQL uses broadcast join (aka broadcast hash join) instead of hash join to optimize join queries when the size of one side data is below .DataFrame [source] ¶.Converting sort-merge join to broadcast join.
.png)