Comment utiliser kafka broker

comRecommandé pour vous en fonction de ce qui est populaire • Avis
Kafka: Les bases pour comprendre et l'utiliser
Ce cluster peut ingérer jusqu'à un million de messages par seconde et délivre jusqu'à 5 millions de .Découvrez comment utiliser les API de consommateur et de producteur Apache Kafka avec Kafka sur HDInsight. À la base, Redis est un magasin de données en mémoire qui peut être utilisé soit comme magasin de valeurs-clés hautes performances, soit comme message broker . Etape 7 : Utiliser Kafka Connect pour importer/exporter des données. La quantité minimale recommandée est de 5 MB par partition Kafka. Je ne pouvais pas trouver tout bon codeur, donc je viens de le configurer pour utiliser la .comKafka, le système de message distribué à haut débit (3/3)blog.
apache-kafka
teamLe guide définitif de Kafka : Tout ce que vous devez savoirfrtips.
Tutoriel : Diffusion en continu Apache Spark et Apache Kafka
En effet, pour fonctionner, de nombreux sys. Tutoriel Kafka : les premiers pas avec Apache Kafka. Cet outil n'est pas adapté au traitement d'un petit volume de messages journaliers. Dans un premier temps, pour utiliser le module Kafka vous avez besoin d’une application créée avec JHipster.
Installation et configuration du connecteur Kafka
À l'origine, elle fut développée en interne par LinkedIn en guise de queue de.
Le logiciel open source Apache Kafka compte parmi les meilleures solutions pour stocker et . Initialement conçue comme une file d'attente de .
Tutoriel Apache Kafka : installation et configuration
Quarkus utilise le projet SmallRye Reactive Messaging pour interagir avec Apache Kafka.Découvrez comment utiliser la fonctionnalité de mise en miroir d’Apache Kafka pour répliquer des rubriques sur un cluster secondaire. processing de grandes quantités . * Configurer Kafka et ses brokers en mode cluster - WIndow/Linux. Once received, the brokers will store the events in a durable and fault-tolerant manner for as long as you need them.Jusqu'à présent, on a vu comment utiliser Kafka sur une machine locale : ce genre d'infrastructure est suffisante pour réaliser des tests, mais en production on va . Le traitement de données en . Pour vos suggestions et commentaires, un espace est créé sur le forum : Commentez. Voici mon log4j.Apache Kafka expliqué en 5 minutes ou moins. Depuis 3 ans, une grande quantité de tweets sur la Covid-19 a été posté sur Twitter.les propriétés.
Comment installer Apache Kafka sur Debian 10
Cela s’ajoute aux RAM requises pour toute autre tâche effectuée par Kafka Connect. L’API de consommateur Kafka permet aux applications de lire des flux de données à partir du cluster. Cette application utilise le package kafka-node pour communiquer avec Kafka.
Kafka avec docker-compose

Pour obtenir des explications détaillées sur les configurations disponibles, consultez . Il vous expliquera également comment utiliser les utilitaires inclus pour envoyer et recevoir des messages avec Apache Kafka.Connect API permet d'implémenter des connecteurs qui récupèrent les données d'un système source ou d'une application vers Kafka ou qui poussent de Kafka vers une . Un serveur Kafka que l'on .Comment utiliser Apache Kafka sur votre machine locale Vous êtes maintenant prêt à commencer à utiliser Apache Kafka sur votre ordinateur local pour .Il s’agit, comme le générateur principal JHipster, d’un package npm. Vous installerez alors facultativement KafkaT pour surveiller Kafka et mettre en place un cluster multi-noeuds Kafka.La plateforme Apache Kafka est souvent déployée sur le système de gestion des conteneurs Kubernetes, utilisé pour automatiser le déploiement, la mise à l'échelle et l'exploitation des conteneurs sur les clusters d'hôtes.8 Log4j appender et je suis incapable de le faire.Dans ce guide de démarrage rapide, vous allez apprendre à créer un cluster Apache Kafka à l’aide du portail Azure.
The Basics of Apache Kafka Brokers
Créez votre première application avec Kafka. Bénéficiez gratuitement de toutes les . Etape 6 : Configurer un cluster multi-broker.Pour exécuter Kafka, nous avons besoin de lancer deux composants : Zookeeper, qui est le gestionnaire de cluster de Kafka. Et depuis, cela ne s .Broker de messages Kafka, retour d'expérience - InfoQinfoq.Apache Kafka est une plateforme de streaming d’événements distribuée capable de gérer des trillions d'événements chaque jour. Le moyen le plus rapide de commencer à .js hébergée dans AKS pour vérifier la connectivité avec Kafka. Bon nombre de modules fournissent des exemples de tableau de bord qui vous permettent d'utiliser ces données. Je suis en train de lancer Kafka-0. L'exécution d'Apache Kafka sur Kubernetes va de pair avec le développement cloud-native, qui constitue la nouvelle .
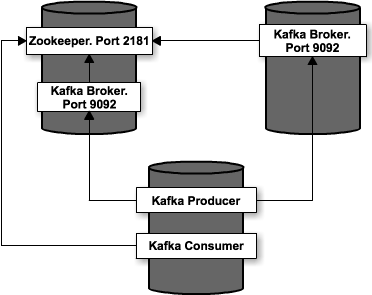
L’avenir de Zookeeper dans une architecture Kafka
If you’re using Python and ready to get hands-on with Kafka, then you’re in the .Le logiciel Apache Kafka est une application open source de la fondation Apache, compatible avec toutes les plateformes, et dont la principale fonction est la .Kafka, Les Bases
Kafka pour les débutants
Il suffit pour cela d’installer JHipster globalement avec npm install -g generator-jhipster puis de créer un dossier et lancer JHipster avec mkdir app . L’API de producteur Kafka permet aux applications d’envoyer des flux de données au cluster Kafka. In a contemporary deployment, these may not be separate . Dans cet article, vous utilisez la mise en miroir pour . Il l’utilise également pour assurer l’élection d’un broker en tant .8 Log4j appender. J'ai moi-même utilisé Kafka de façon professionnelle pendant plusieurs années, cela . Nous allons essayer de comprendre ce qui explique la success-story de .Ce tutoriel expliquera comment installer Kafka à l'aide de Docker puis lancer un premier programme en Java. * Utiliser les scripts kafka pour produire et consommer des messages. Cet exemple est basé sur le client Python Apache Kafka de Confluent, modifié en vue d’une utilisation avec Event Hubs pour Kafka. Ce tutoriel n’a pas vocation à expliquer le fonctionnement de Kafka. Nous verrons étape par étape comment y arriver.
Créez votre première application avec Kafka
Quels sont les avantages de Kafka ?L'utilisation de Apache Kafka apporte plusieurs avantages majeurs pour les entreprises. Avec linux / docker Dans votre . Si le sujet n'existe pas, créez-le en affectant .Qu'est-ce que Apache Kafka ?Apache Kafka est une plateforme de streaming de données open source.Microsoft utilise aussi un cluster de plus de 1000 brokers Kafka.1 en toute sécurité sur un serveur Debian 10, puis tester votre installation en produisant et en consommant un message Hello World.comKafka, le système de message distribué à haut débit (1/3)blog.En effet, Kafka utilise Zookeeper pour stocker de nombreuses informations en tant que métadonnées sur les partitions et les brokers.Les modules intégrés à Filebeat et Metricbeat facilitent la configuration et le monitoring d'un cluster Kafka. La configuration bootstrap.teamKafka : le message broker essentiel pour une gestion agile .Apache Kafka bénéficie également de la portabilité de Kubernetes entre les fournisseurs d'infrastructure et les systèmes d'exploitation. Je veux que mon application pour envoyer connectez-vous directement à kafka par Log4j appender.servers définit le ou les serveurs kafka à adresser lors de la création du producer.
Ce guide de démarrage rapide montre comment créer un point de terminaison Event Hubs Kafka et s’y connecter à l’aide d'un exemple de producteur et de consommateur écrit en Python.
Déployez et administrez un cluster Kafka
Apache Kafka pour débutant
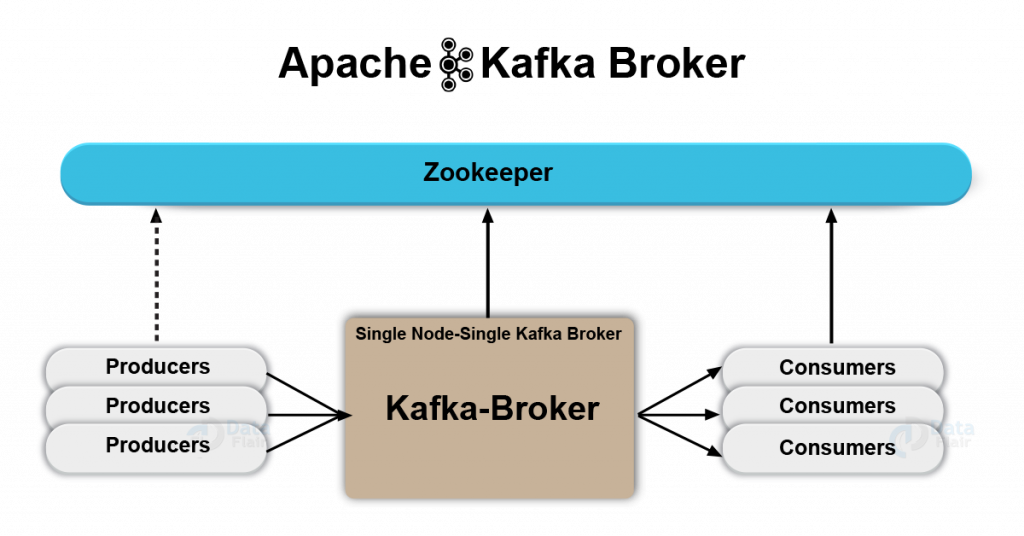
Bienvenue sur l’école 100% en ligne des métiers qui ont de l’avenir.Kafka fonctionne sous forme de clusters : pour assurer une haute disponibilité (le moins d'interruption de service possible), on utilise plusieurs brokers, c'est-à-dire plusieurs .Dans cet article. Il utilise une architecture pub-sub pour la distribution de messages, des topics et des partitions pour le stockage et la distribution des données, des producteurs et des consommateurs pour envoyer et récupérer des .Apache Kafka est un système de streaming distribué conçu pour gérer de grandes quantités de données en temps réel. This blog post introduces the various components of the Confluent ecosystem, walks you through sample code, and provides suggestions on your next steps to Kafka . Enfin, Kubernetes permet aux clusters Apache Kafka de couvrir les environnements sur site ainsi que les clouds publics, privés et hybrides, et d'utiliser plusieurs systèmes d'exploitation. * Configurer et utiliser des kafka connect source et sink. Grâce à sa scalabilité et sa faible latence, Kafka peut gérer de grandes . Alors qu'un nombre croissant d'entreprises utilisent le Big Data en temps réel pour obtenir des informations et prendre des décisions fondées sur les données, il est nécessaire de disposer d'un outil résilient pour process ces données en temps réel augmentent également.Apache Kafka est une plateforme de traitement de données en streaming temps réel.Apache Kafka utilise un système de diffusion des brokers et pour pouvoir s'y connecter en local, c'est mieux de connaitre l'adresse IP de ces derniers pour pouvoir les insérer dans la variable d'environnement KAFKA_ADVERTISED_LISTENERS prévue à cet effet. Unlike Amazon Kinesis and Google PubSub where a message can be stored for a maximum of 7 days, Apache Kafa can act as a . Etape 3 : Créer un topic.
Etape 4 : Envoyer quelques messages.
Pourquoi exécuter Apache Kafka sur Kubernetes
If you’re using Python and ready to get hands-on with Kafka, then you’re in the right place. Premiers pas avec Quarkus .Il peut être utilisé pour collecter, traiter et distribuer des données en continu. Il exploite également de nombreuses . Etape 2 : Démarrer le serveur.Dans ce tutoriel, vous allez installer et configurer Apache Kafka 2.Cet article explique comment ingérer des données avec Kafka, à l’aide d’une configuration Docker autonome pour simplifier la configuration du cluster Kafka et du cluster du .Apache Kafka est un outil utilisé dans les systèmes Big Data en raison de sa capacité à gérer un débit élevé et en temps réel.A Kafka client communicates with the Kafka brokers via the network for writing and reading messages. On y retrouve des news, des réflexions, l’expression de sentiments ou d’opinion et tant d’autres choses.Kafka utilise le concept très connu du publish / subscribe, mais en s’appuyant sur le disque dur pour fonctionner. Cet outil est conçu pour répondre à trois besoins spécifiqu.From a physical infrastructure standpoint, Apache Kafka is composed of a network of machines called brokers. Etape 1 : Télécharger le code. Découvrez tout ce qu'il ya a à savoir pour maitriser Kafka. Dans ce tutoriel, vous allez diffuser des données en continu à partir de Spark sur HDInsight, à l’aide d’un notebook . Initialement conçue comme une file d'attente de messagerie, Kafka est basée sur une abstraction d'un journal de validation distribué.Comment intégrer Kafka dans Quarkus. Les étapes de ce document utilisent une application Node. On l'utilise pour le traitement de données en temps réel. Vous pouvez exécuter la mise en miroir en tant que processus continu, ou par intermittence, pour migrer des données d’un cluster vers un autre.
Apache Kafka : tout savoir sur le Data Streaming
Broker Kafka Un cluster Kafka est constitué d’un ou de plusieurs serveurs (broker Kafka) fonctionnant sous Kafka.Kafka comprend plusieurs éléments disparates : le service en lui-même est souvent composé de divers brokers et instances ZooKeeper, mais aussi des clients qui .Découvrez comment utiliser Azure Kubernetes Service (AKS) avec Apache Kafka sur un cluster HDInsight.
[Kafka][Symfony] Utiliser KAFKA
Pour mieux comprendre comment Kafka fonctionne, voici un exemple simple d’utilisation : Producteur de Messages : Supposons que vous avez un système de surveillance de capteurs IoT qui génère.

Démarrage rapide.Quelles sont les limites de Kafka ?Néanmoins, Kafka ne convient pas à toutes les situations.Bienvenue, amateurs du numérique et de l’informatique !
Métamorphosez vos applications temps réel avec Kafka
Il n’est pas nécessaire ici de déclarer l’ensemble des brokers du cluster, mais la bonne pratique est d’en déclarer 3 – si l’un des brokers est indisponible, le producer pourra toujours essayer de se connecter au cluster par un autre .











