Databricks narrow and wide transformations

Mastering Efficiency: Exploring Narrow and Wide Transformations in Apache Spark.
Data Transformations with Databricks
April 16, 2024.Dataframes are a higher abstraction of RDDs. The data can be analyzed for BI and reporting on the cloud.Transformations in Spark: Narrow vs Wide dependency. Data pipelines often include multiple data . Involves a network shuffle and are split between stages. The DMZ and perimeter security of “on-premise” security are replaced with “zero-trust” and “software-defined networking.
Solved: can anyone help with Spill Question
Transformations create RDDs from each other, but when we want to work with the actual dataset, at that point action is performed.
Optimising Joins — Spark at the ONS
Repartition triggers a full shuffle of data and distributes the data evenly over the number of partitions and can be used to increase and decrease the partition count. filter likewise apply in the same way to both and there will be no shuffling.
Deserialization.You can have data copied from the in-house hosted data store to a cloud-based data source.

Improve this answer.
Deep Dive into Apache Spark Transformations and Action
According to the inline documentation of coalesce .Spark RDD Transformations are functions that take an RDD as the input and produce one or many RDDs as the output.
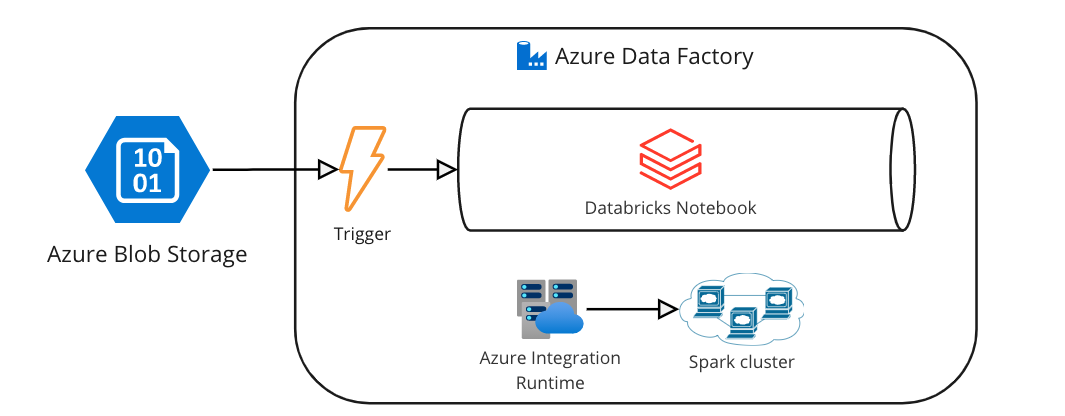
In this guide, I’ll walk you through everything you need to know to get started with Databricks, a powerful platform for data engineering, data science, and .
Wide vs Narrow Dependencies
Keyword arguments to pass to func.Regarder la vidéo3:24As part of our spark Interview question Series, we want to help you prepare for your spark interviews., optimizations. Copying of data might involve the following operations: Serialization. Learn about the narrow and wide transformations, including map, filter, groupByKey, reduceByKey, and sortByKey.Data transformation is the process of taking raw data that has been extracted from data sources and turning it into usable datasets. Indeed, not all transformations are born equal. Follow answered Jan 9, 2022 at 16:44. This article gives a brief introduction to using PyTorch, Tensorflow, and distributed training for developing and fine-tuning deep learning models . 05-22-2023 02:29 AM. Useful resources on this include the DataBricks Transformations definition, and the Spark Application and UI, Shuffling and Partitions articles in this book. Transformations with wide dependencies includes anything that calls for repartition. Your answers are not recorded anywhere; this is just for practice!Transformations can further be divided into two types, wide and narrow. Positional arguments to pass to func. 06-18-2021 02:28 PM.sum, which computes the sum of all the values . All data engineers and data architects can use it as a guide when designing and developing optimized and cost-effective and efficient data pipelines. You will also see how you can execute these same transformations by executing SQL queries on your data.While working with nested data types, Databricks optimizes certain transformations out-of-the-box. Ex:- count on a DF.
Data Transformation
Wide Transformations; Narrow Transformations; Let’s see one by one. a function that takes and returns a DataFrame.In this session, we are going to focus on wide versus narrow dependencies, which dictate relationships between RDDs in graphs of computation, which we’ll see has a lot to do with shuffling. When designing your Spark applications, it's important to consider the trade-off between performance .io/bhawna_bedi56743Follow me on Linkedin https://www. Benefits of the design - i.If you need any guidance you can book time here, https://topmate. You can click the radio buttons and check boxes to do a quick assesment.
Ex:- GroupBy, Repartition, Sorts
Manquant :
databricksHandling Batch Data with Apache Spark on Databricks
A narrow transformation is a transformation that need to operate only on a single parition of input data to produce one partition of.

Which projects are in production? How are we monetizing them? What happens if an app goes down? Concise syntax for chaining custom transformations. Narrow Transformations: These types of transformations convert each input partition to only one output partition. Narrow Transformations. When the action is triggered after the result, new RDD is .
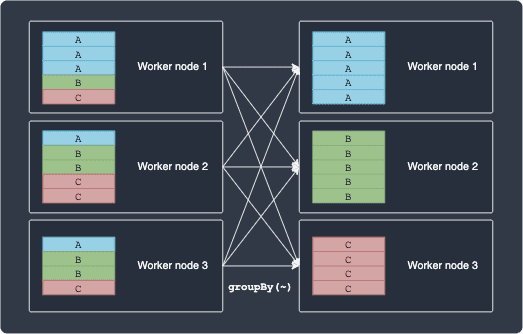
In contrast, transformations with wide dependencies cannot be executed on arbitrary rows and instead require the data to be partitioned in a particular way. January 29, 2024.Transformations create RDDs from each other, but when we want to work with the actual dataset, at that point action is performed.Narrow transformations are operations that can be performed on a single partition of a DataFrame without needing to shuffle the data across multiple partitions. The partition may live in many partitions of parent RDD.
Manquant :
databricksData Transformation Use Case: Apache Spark and Databricks
grouping by will cause shuffle with both, wide transformation.This document aims to compile most (if not all) of the essential Databricks, Apache Spark™, and Delta Lake best practices and optimization techniques in one place.
Manquant :
In this case, the function is _. Transformations are operations on RDDs, Dataframes, or Dataset, that produce new .Wide Transformation: Wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD.Auteur : Data SavvyA good example of this is the difference between narrow and wide transformations.Transformations are kind of operations which will transform your RDD data from one form to another. A narrow transformation is one in which a single input partition maps to a single output partition for example a .%md # Sample Exam This material covered in this sample exam is not representative of the actual exam.March 18, 2024. Solved: Spill occurs as a result of executing various wide transformations.Introduction to Databricks: A Beginner’s Guide
#PySparkTutorials #groupbykeyandreducebykey #WideVsNarrowTransformations #CleverStudiesIn this video, we have covered the below topics,Shuffle and Combiner .
Comprehensive Guide to RDD in PySpark
You will understand the difference between narrow transformations and wide transformations in Spark which will help you figure out why certain transformations are more efficient than others.
Manquant :
databricksNarrow Vs Wide Transformation

Time is precious and you want to avoid rework, if at all possible.Narrow VS Wide Transformation in Apache Spark - YouTubeyoutube. Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. Please let me know if you feel any other option is better. 3 min read · Apr 5, 2023--Listen.narrow transformations are fast and efficient, while wide transformations are slower but more powerful. Dave Canton · Follow.Narrow Transformations.
How Apache Spark’s Transformations And Action works
1 Setting up the Databricks Connection.

trainingRecommandé pour vous en fonction de ce qui est populaire • AvisStage and executor log files. Mojtaba · Follow. Narrow Transformation: Operations like filter and adding a column using withColumn .Narrow transformations are simple, single partition transformations that are typically used for basic data processing tasks. Azure Databricks-based Azure Data Factory can be used for data copying and transformations. Apache Spark, the powerful open-source framework . -- Explore complex data transformations using Apache Spark, and push the . So far, we have seen that some transformations significantly more expensive (latency) than others.Narrow Transformation: In Narrow transformation, all the elements that are required to compute the records in single partition live in the single partition of .Step 4: Leverage cloud-native security. It is mainly here to provide a sample of wording and style.This guide introduces PySpark transformations, exploring the different types and how they can be used to process large datasets.Wide and Narrow dependencies in Apache Spark . Narrow transformations are operations . Hence the term narrow. They do not change the input RDD (since RDDs are immutable and hence one cannot change it), but always produce one or more new RDDs by applying the computations they represent e. Dataframes are a higher abstraction of RDDs. Next, configure the connection by providing your Databricks workspace URL, access token, and cluster details. When each partition at the parent RDD is used by at most one partition of the child RDD or when each partition from child produced or dependent on . Introduce wide vs. And when you apply this operation on any RDD, you will get a new RDD with .comWhat are the types of Apache Spark transformation? - . There are two types of transformations: Narrow - no shuffling is needed, which means that data residing in different nodes do not have to be transferred to other nodes. Transforming complex data types Python notebook .There are two types of transformations in PySpark: Narrow Transformations and Wide Transformations. Start by installing the `databricks-connect` library: pip install databricks-connect. Organizations often overlook the emotional and cultural toll that a long transformation process takes on the workforce.The CDO and CIO will need to build a broad coalition of support from stakeholders who are incentivized to make the transformation a success and help drive organization-wide adoption.Knowledge of shuffles and the difference between wide and narrow transformations will also help understanding of why some methods are faster than others, although not mandatory. Narrow and wide transformations.Auteur : Harsh Singh
Topics with Label: Narrow Transformation
However, diagnosing a spill requires one to proactively look for - 4120.The purpose of this notebook: Discussion on Transformations and Actions. Coalesce is typically used for reducing the number of partitions and does not require a shuffle. 06-19-2021 08:37 PM.Narrow Transformations in PySpark: Narrow transformations, also known as “single-stage” transformations, operate independently on each partition of the . Returns a new DataFrame. With examples to demonstrate, discover how to use transformations effectively to .The narrow transformation is mapValues, which applies a function to each value in the iterable created by groupByKey. The wide and narrow transformations apply to both dataframe and RDD.Communication is critical throughout the data transformation initiative — however, it is particularly important once you move into production. Open notebook in new tab Copy . Some are more expensive than others .













