Dataframe to parquet
So far I have not been able to transform the dataframe directly into a bytes which I then can upload to Azure.read_sql_query(write_parquet( file: str | Path | BytesIO, *, compression: ParquetCompression = 'zstd', compression_level: int | None = None, statistics: bool = True, row_group_size: int | .retrieve data from a database, convert it to a DataFrame, and use each one of these libraries to write records to a Parquet file. I am reading data in chunks using .I need to save this as parquet partitioned by file name.I have a pandas dataframe and want to write it as a parquet file to the Azure file storage. ‘append’ (equivalent to ‘a’): Append the new data to existing data.0' ensures compatibility with older readers, while '2.
Tutorial: Load and transform data using Apache Spark DataFrames
The string could be a URL.I am reading data in chunks using pandas.partitionBy(Filename).

parquetFile <-read.parquet as pq; df = pq. Esta función escribe el marco de datos como parquet file.rand(6,4)) df_test. It is particularly . For file URLs, a host is expected.# The result of loading a parquet file is also a DataFrame.使用Pandas将DataFrame数据写入Parquet文件并进行追加操作 在本篇文章中,我们将介绍如何使用Pandas将DataFrame数据写入Parquet文件,以及如何进行追加操作。 阅读更多:Pandas 教程 Parquet文件格式 Parquet是一种二进制列式存储格式,设计用于具有复杂数据结构的大数据文件。 The syntax for this method is as follows:
Write out spark df as single parquet file in databricks
PathLike[str] ), or file-like object implementing a binary read() function.<= 19) head .to_pandas() – . 有关详细信息,请参阅 .I'm pretty new in Spark and I've been trying to convert a Dataframe to a parquet file in Spark but I haven't had success yet. Viewed 4k times. Notice that all part files Spark creates has parquet extension. This function writes the dataframe as a parquet file.
Python: save pandas data frame to parquet file
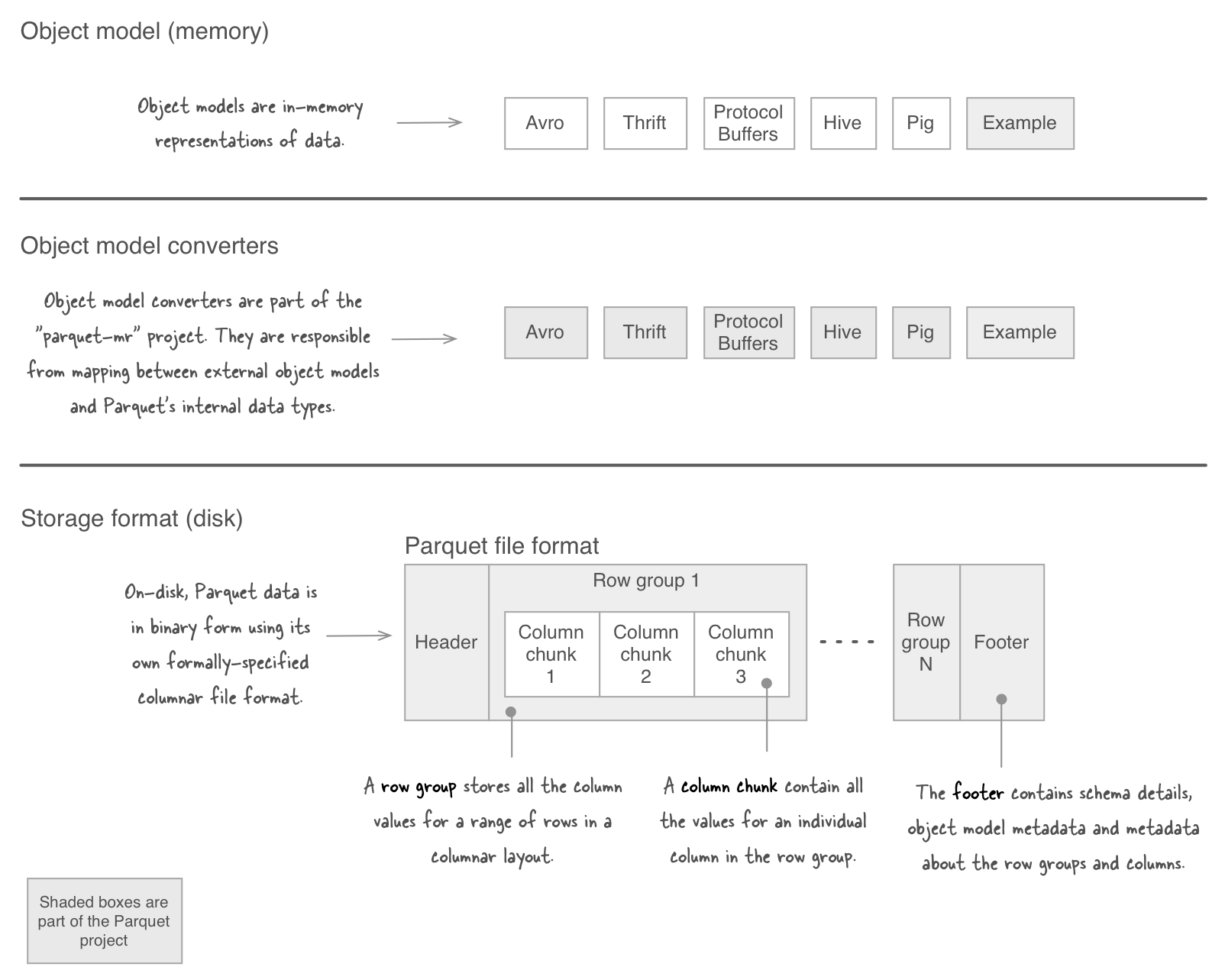
How the dataset is partitioned into files, and those files into row-groups.to_parquet(fname, engine='auto', compression='snappy', **kwargs) [source] ¶.to_parquet函数方法的使用.to_parquet('myfile.2 Spark Read Parquet file from Amazon S3 into DataFrame .
4 Ways to Write Data To Parquet With Python: A Comparison
to_parquet (path=Aucun, moteur='auto', compression='snappy', index=Aucun, partition_cols=Aucun, storage_options=Aucun, .Writing Pandas DataFrame to Parquet file? Asked 2 years, 3 months ago.This metadata may include: The dataset schema.dataframe as da.to_parquet(路径=无,引擎='自动',压缩='snappy',索引=无,partition_cols=无,storage_options=无,**kwargs) [source] 将 DataFrame 写入二进制 parquet 格式。.parquet as pq for chunk in pd. String, path object (implementing os. Valid URL schemes include http, ftp, s3, gs, and file. write_table() has a number of options to control various settings when writing a Parquet file.これらはすべて、parquet ファイルを Pandas DataFrame に読み込むために必要な前提条件です。 寄木細工のファイルをデータ フレームに読み込むには、read_parquet() メソッドが使用されます。 開発者の要件に応じて追加または使用できる 5つのパラメーターがあります。
Read and Write Parquet file from Amazon S3
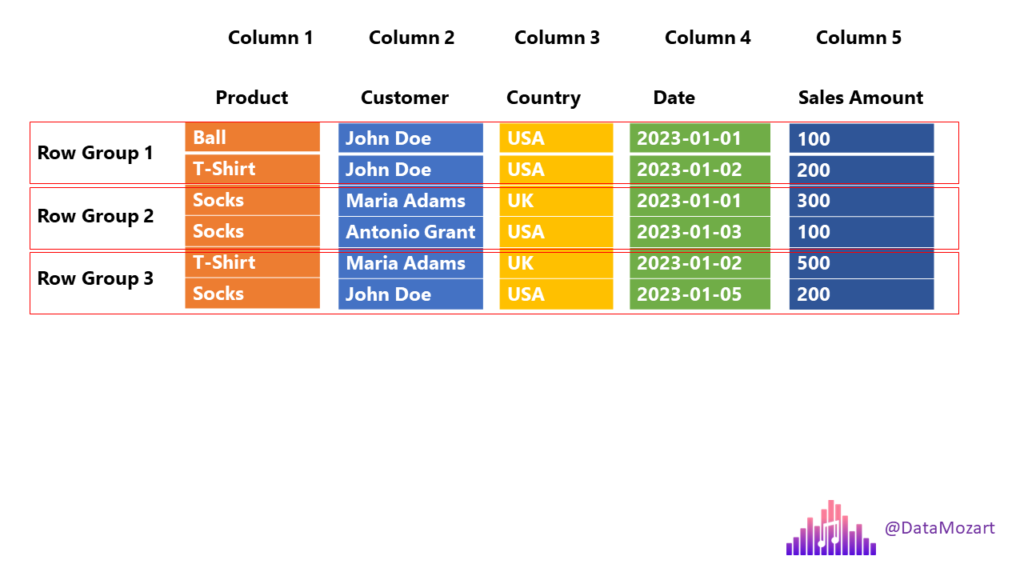
By the end of this article, you’ll have a thorough understanding of how to use Python to write Parquet files and unlock the full power of .How do I save the dataframe shown at the end to parquet? It was constructed this way: df_test = pd.PySpark:将Spark DataFrame写入单个Parquet文件 在本文中,我们将介绍如何将PySpark DataFrame写入单个Parquet文件。PySpark是Apache Spark在Python上的API,提供了用于分布式数据处理和分析的丰富功能和工具。Parquet是一种列式存储格式,适用于高效地处理大规模数据集。 阅读更多:PySpark 教程 为什么选择Parqto_parquet(path: str, mode: str = 'overwrite', partition_cols: Union [str, List [str], None] = None, compression: Optional[str] = None, index_col: Union [str, List [str], None] .Write the DataFrame out as a Parquet file or directory. Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。.
pandas API on Spark
Parquet file on Amazon S3 3.

Some parquet datasets include a _metadata file which aggregates per-file metadata into a single location.dataframe (using df = dd.mode(overwrite). Will be used as Root Directory path while writing a partitioned dataset.What Are Apache Parquet files?
5 Efficient Ways to Convert a pandas DataFrame to Parquet
However, when I run the script it shows me: AttributeError: 'RDD' object has no attribute 'write' from pyspark import SparkContext sc . Pandas提供了大量能使我们快速便捷地处理数据的函数和 . Here are the first three rows of the file: .to_parquet(path=Aucun, moteur='auto', compression='snappy', index=Aucun, partition_cols=Aucun, storage_options=Aucun, **kwargs) Écrivez un DataFrame au format parquet binaire.Converting a DataFrame to a Parquet file is straightforward. import pandas as pd . I am developing a Jupyter Notebook in the Google Cloud Platform / Datalab. 您可以选择不同的镶木地板后端,并可以选择压缩。.makedirs(path, exist_ok=True) # write append (replace the naming logic with what works for you) filename = f'{datetime.6+, AWS has a library called aws-data-wrangler that helps with the integration between Pandas/S3/Parquet.The to_parquet of the Pandas library is a method that reads a DataFrame and writes it to a parquet format.

str: Required: engine Parquet library to .Writing Spark DataFrame to Parquet format preserves the column names and data types, and all columns are automatically converted to be nullable for compatibility reasons. Depending on your dtypes and number of columns, you can adjust this to get files to the .The syntax for this method is as follows: DataFrame.read_sql and appending to parquet file but get errors Using pyarrow. Before learning more about the to_parquet method, let us dig deep into what a Parquet format is .Pandas如何将DataFrame以append的方式写入Parquet文件 在本文中,我们将介绍Pandas如何将DataFrame以append的方式写入Parquet格式的文件。Parquet是一种列式存储格式,被广泛应用于大数据处理和机器学习领域。使用Parquet格式存储数据可以有效地提高数据读取和处理的效率,同时也可以节约存储空间。
Parquet ファイルを Pandas DataFrame に読み込む
parquet function to create the file.
to_parquet(ruta=Ninguno, motor='auto', compresión='snappy', índice=Ninguno, partición_cols=Ninguno, opciones_almacenamiento=Ninguno, **kwargs) Escriba un DataFrame en formato parquet binario.to_parquet(save_dir) This saves to multiple parquet files inside save_dir, where the number of rows of each sub-DataFrame is the chunksize.You can now use pyarrow to read a parquet file and convert it to a pandas DataFrame: import pyarrow.parquet: import pyarrow as pa import pyarrow. Cette fonction écrit la trame de données sous la forme d'un parquet file. Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。. Vous pouvez choisir différents backends de parquet et avoir la possibilité de .parquet) # Parquet files can also be used to create a temporary view and then used in SQL statements. First ensure that you have pyarrow or fastparquet installed with pandas. I have created a Pandas DataFrame and would like to write this DataFrame to both Google Cloud Storage(GCS) and/or BigQuery. Performance : It’s heavily optimized for complex nested data structures and . Here is how you can do it: Example in pandas. Write a DataFrame to the binary parquet . Pandas has a core function to_parquet().Suppose you have a Parquet file with 9 columns and 1 billion rows of data.Parquet is a columnar storage format that is designed to optimise data processing and querying performance while minimising storage space. To append to a parquet object just add a new file to the same parquet directory.
Mastering the Conversion of Pandas DataFrames to Parquet Format
Hello and thanks for your time and consideration.Why Choose Parquet? Columnar Storage : Instead of storing data as a row, Parquet stores it column-wise, which makes it easy to compress and you end up saving storage. Python write mode, default ‘w’.Pandas will silently overwrite the file, if the file is already there. Such as ‘append’, ‘overwrite’, ‘ignore’, ‘error’, ‘errorifexists’.If you need to deal with Parquet data bigger than memory, the Tabular Datasets and partitioning is probably what you are looking for.
PySpark:将Spark DataFrame写入单个Parquet文件
mode can accept the strings for Spark writing mode. The documentation says that I can use write.All files were generated from as many instances of pd.
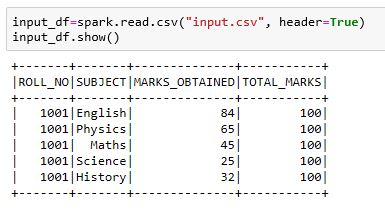
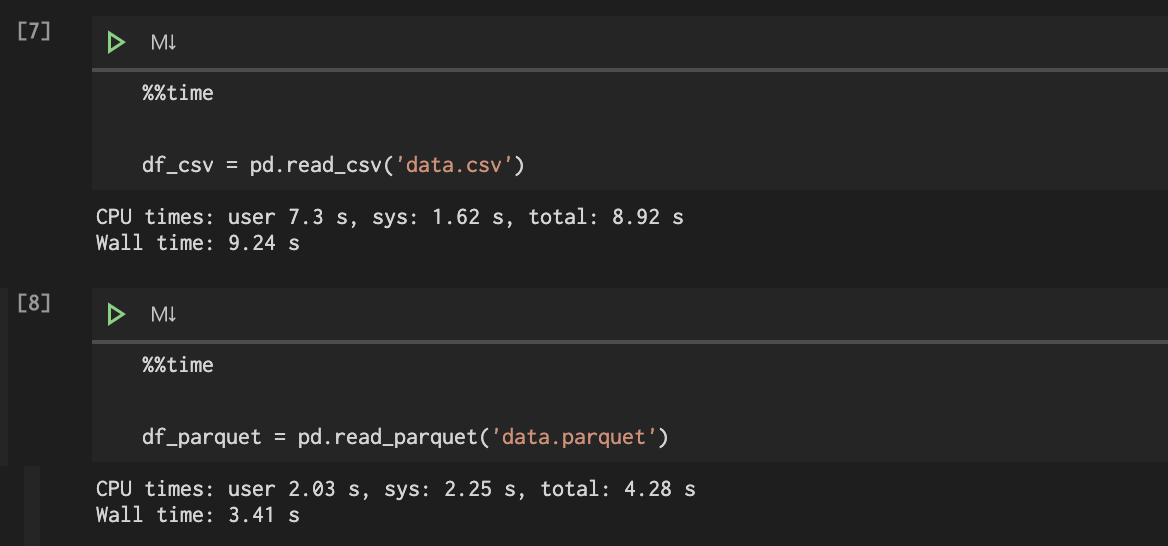
parquet') , I get the following error:本記事は、PythonのライブラリPandasのデータフレームを高効率(高速・低容量)で保存する方法を紹介します。 - 【Python】高効率でデータフレームをローカルに保存する(Pandas. Modified 2 years, 3 months ago.DataFrame, using df. My current workaround is to save it as a parquet file to the local drive, then read it as a bytes object which I can upload to Azure. to install do; .Step 3: Load data into a DataFrame from CSV file. version, the Parquet format version to use. # Creating a sample DataFrame . This is the most straightforward method provided by the pandas library to convert a DataFrame into a . Path to write to.to_parquet(self, fname, engine='auto', compression='snappy', index=None, partition_cols=None, **kwargs) Parameters: Name Description Type / Default Value Required / Optional; fname File path or Root Directory path. Use aws cli to set up the config and credentials files, located at .read_table('dataset. When read_parquet() is used to read multiple files, it first loads metadata about the files in the dataset. Load a parquet object from the file path, returning a DataFrame.parquet') You still need to . Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model, or programming language. Persisting a Spark DataFrame is wise in .







