Difference between orc and parquet
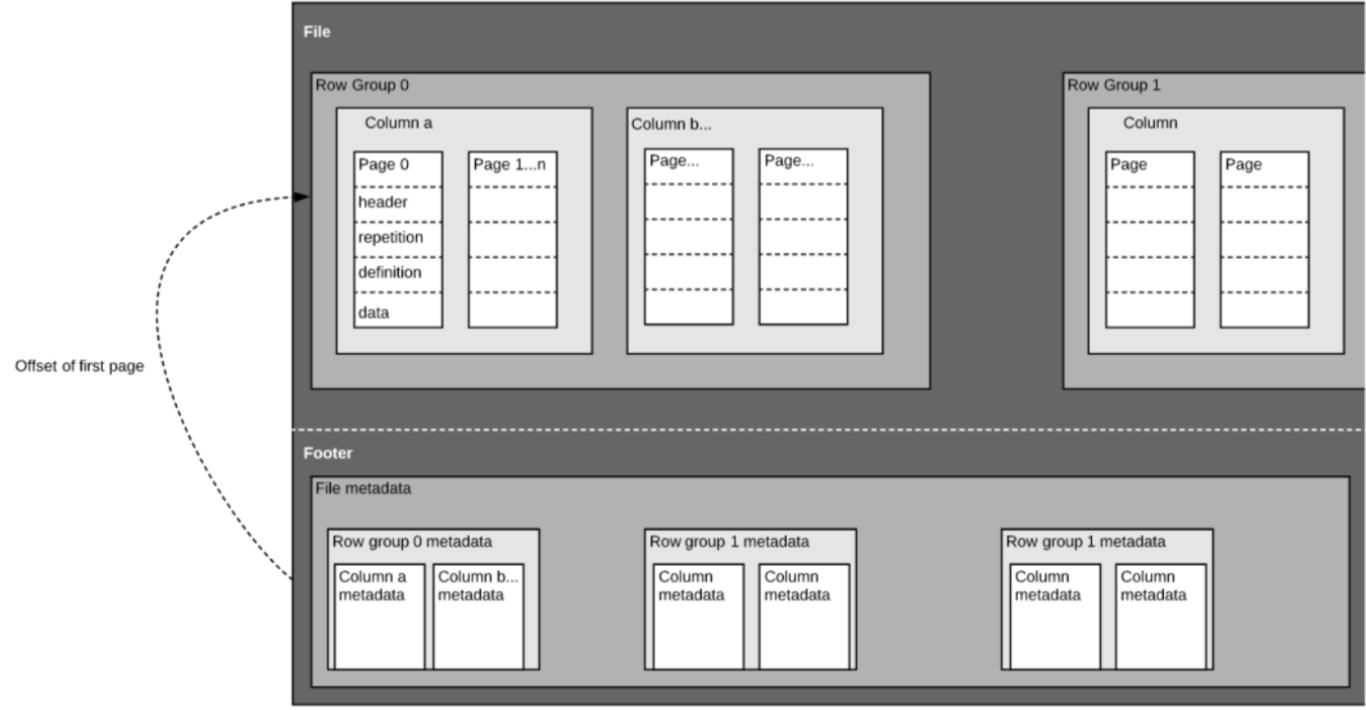
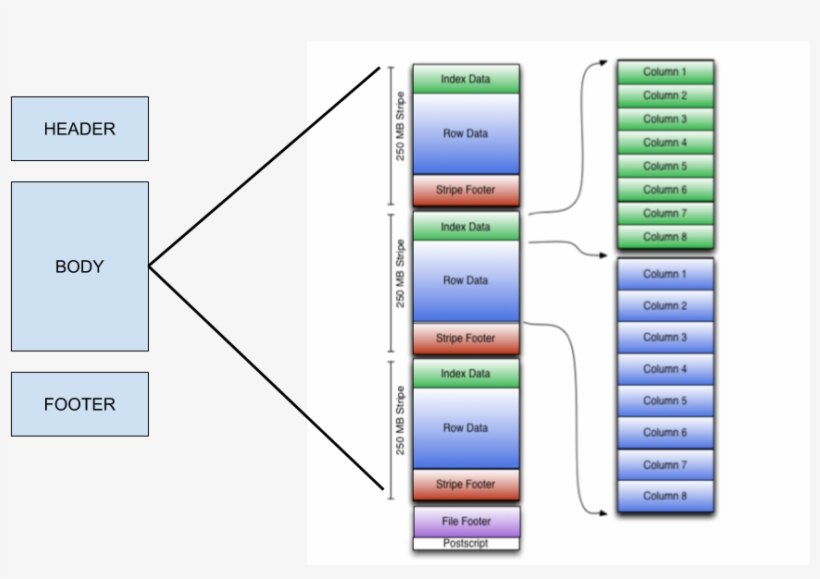
They have more in similarity as compare to differences.Here are the differences between ORC and Parquet.You can take an ORC, Parquet, or Avro file from one cluster and load it on a completely different machine, and the machine will know what the data is and be able to process it.ORC files are made of stripes of data where each stripe contains index, row data, and footer (where key statistics such as count, max, min, and sum of each column are conveniently cached).Apache Hive supports several familiar file formats used in Apache Hadoop. Parquet flooring tends to be more expensive, ranging from $20 to $45 per square foot, compared to hardwood flooring which costs about $6 to $23 per square foot.This post isn’t an Iceberg vs Parquet comparison, as the two do different things.What are the differences between ORC, AVRO, and Parquet files? Understanding the Question.Avro is a Row based format.ORC vs Parquet formats | CDP Private Cloud. If your data consists of a lot of columns but you are interested in a subset of columns then you can use Parquet.Now, let's dive into a head-to-head comparison between Apache Iceberg and Apache Parquet.In this paper, file formats like Avro and Parquet are compared with text formats to evaluate the performance of the data queries. ORC and Parquet provide .Issue when executing a show create table and then executing the resulting create table statement if the table is ORC. As we mentioned earlier, Iceberg's schema evolution capabilities are one of its .The CSV data can be converted into ORC and Parquet formats using Hive. In addition to being file formats, ORC, Parquet, and Avro are also on-the-wire formats, which means you can use them to pass data between nodes in your Hadoop . However, they both collect metadata about your data. In this article, we will discuss what SPC flooring and parquet are, the differences, and which .Difference between ORC, Avro, and Parquet Devikiran Gadanki 3y Performance of Avro, Parquet, ORC with Spark Sql Konstantine Kougios 4y Tuning Hbase for Optimized Performance - Part 1 .Similar to ORC, another big data file format, Parquet also uses a columnar approach to data storage.Explore the differences between Avro, Parquet, and ORC.
Demystify Hadoop Data Formats: Avro, ORC, and Parquet
We did some benchmarking with a larger flattened file, converted it to spark Dataframe and stored it in both parquet and ORC format in S3 and did querying with **Redshift-Spectrum **.
Pickle, JSON, or Parquet: Unraveling the Best Data Format for
Working with Delta Lake. [Update]
ORC vs Parquet
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. By downloading this paper, you’ll gain a comprehensive . While both these flooring options have unique features, they have several differences making them suitable for different spaces and lifestyles.Parquet files are often much smaller than Arrow-protocol-on-disk because of the data encoding schemes that Parquet uses. Learn when to use each format for optimal performance and efficiency.In this blog post, I will explain 5 reasons to prefer the Delta format to parquet or ORC when you are using Databricks for your analytic workloads.ORC (Optimised Row Columnar) is also a column-oriented data storage format similar to Parquet which carries a schema on board. Without compression, Parquet still uses encodings to shrink the data.What are the pros and cons of the Apache Parquet format compared to other formats? Asked 8 years ago. Vectorization means that rows are decoded in batches, dramatically improving memory locality and cache utilization. Using Apache Hive.The biggest difference between ORC, Avro, and Parquet is how they store the data. Parquet and ORC both store data in columnar format, while Avro stores data in a row-based format. The differences between Optimized Row Columnar (ORC) file format for storing .
Different file formats in Hadoop and Spark
Schema Evolution.This post explains the differences between Delta Lake and Parquet tables and why Delta Lakes are almost always a better option for real-world use cases.Table of contents.As a customer, one will always be curious to know the difference between SPC flooring and parquet. Using show create table, you get this: STORED AS INPUTFORMAT ‘org.OrcInputFormat’ OUTPUTFORMAT ‘org. Hive has a vectorized ORC reader but no vectorized parquet reader and spark has a vectorized parquet reader and no .
Open file formats: Parquet, ORC, Avro
it means that like Parquet it . The question asks for a comparison of three prominent data file formats used in big data applications. When to use which file format? . ORC and Parquet are very Similar File Formats. Delta is a data format based on Apache Parquet.

SPC Flooring VS Parquet-What is the difference?
It has more libraries and ., adding or modifying columns.
Comparing Performance of Big Data File Formats: A Practical Guide
That’s why using a Delta Lake instead of a Parquet table is almost always advantageous.
Difference Between ORC and Parquet
PARQUET is ideal for .OrcOutputFormat’
Apache Iceberg vs Apache Parquet: Metadata Deep Dive
It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. The same steps are applicable to ORC also. Encodings use a simpler approach than compression and often yield similar results to universal compression for homogenous data. Modified 5 months ago.One key difference between the two is that ORC is better optimized for Hive, whereas Parquet works really well with Apache Spark. Working with Avro. It’s designed for use with Apache Hadoop, and it’s great for data querying and . We'll examine how these file formats handle different aspects of data engineering, such as schema evolution, performance, and data storage. Learn about the differences between organizing data by rows and columns and how it affects .
What are the differences between Avro, Parquet, and ORC
Simply, replace Parquet with ORC. So, in summary, Parquet files are designed for disk storage, Arrow is designed for in-memory (but you can put it on disk, then memory-map .A closer look at the three big data formats: ORC or Optimized Row Columnar file format. Parquet Format Cumulative CPU - 211. Working with ORC. In fact, Parquet is the . Avro is fast in retrieval, Parquet is much faster. These are the steps involved.statistics)See more on stackoverflowCommentairesMerci !Dites-nous en davantageORC and Parquet are widely used in the Hadoop ecosystem to query data, ORC is mostly used in Hive, and Parquet format is the default format for Spark.
Delta Lake has all the benefits of Parquet tables and many other critical features for data practitioners.Download this paper to gain valuable insights into the fundamental concepts and benefits of file formats in the big data realm.

Spark performs best with parquet, hive performs best with ORC. Parquet: Best for large-scale, efficient data storage and complex analytical querying.An open file format is one of the cornerstones of a modern data analytics architecture. The compression efficiency of Parquet and ORC depends greatly on your data.The evolution of data formats and ideal use cases for each type. Text Format Cumulative CPU - 128. The most commonly used encoding for Parquet is .What’s Different. Working with Parquet. The biggest difference between ORC, Avro, and Parquet is how the store the data. What is the Avro file format? Avro is one of the most useful file formats for the data serialization framework in the Spark eco-system because of its .Avro: Avro is a row-based data .Email This PostDifference Between Neuroevolution and Deep LearningDifference Between Elasticsearch and HadoopDifference Between Hadoop and SparkDifference Between Ecobee and Ecobee LiteDifference Between HBase and Hive
Parquet, ORC, and Avro: The File Format Fundamentals of Big Data
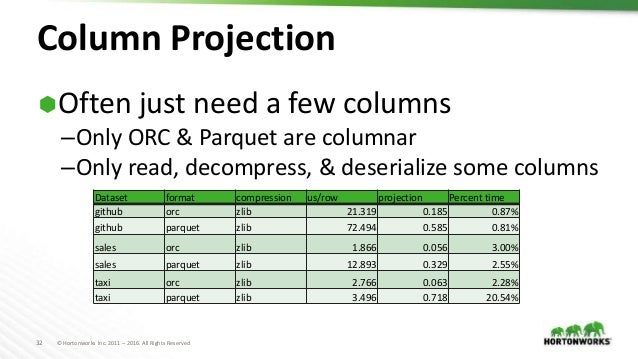
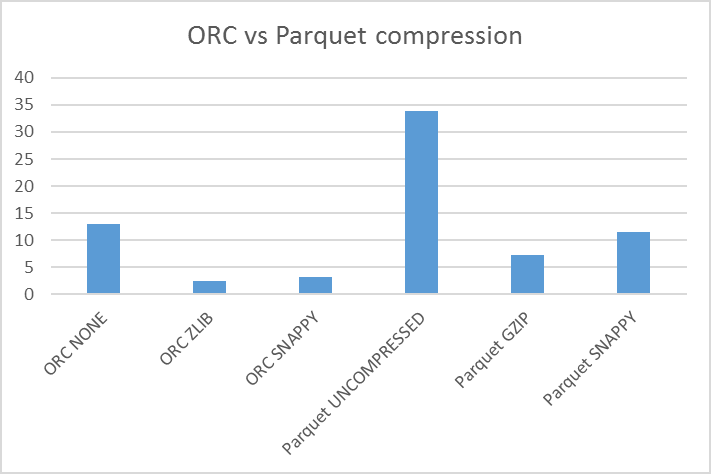
Conclusion : It is clearly visible that, from (1) & (2) , Parquet is taking significantly more Time and Space while creating the file system when compared to ORC.0 release happens, since the binary format will be stable then) Parquet is more expensive to write than Feather as it features more layers of encoding and . Parquet is more widely adopted and supported by the community than ORC. This difference in price is largely due to the complexity of parquet’s design and installation process.Still, both these file formats are way more different than each other. With highly efficient data compression, Parquet files are better in an analytics system’s write-once, read-many conditions.Gain insights into the distinctions between ORC and Parquet file formats, including their optimal use cases. Which indicates that, Parquet . Unlike text-based formats, these binary formats optimize reading and writing workloads . The interviewer may be trying to assess the candidate’s technical knowledge of these file formats and their ability to compare and . If your disk storage or network is slow, Parquet is going to be a better choice.
Big Data Formats: Understanding Avro, Parquet, and ORC
Average of a column operation.In the data world, Parquet is a columnar storage format, similar to ORC, but it organizes data more efficiently.PARQUET only supports schema append, whereas AVRO supports a much-featured schema evolution, i.parquet')print(parquet_file. Different data query patterns have been evaluated. Both are Columnar File systems. This is a columnar file . ORC Format Cumulative CPU - 165.In summary, ORC, RC, Parquet, and Avro all have their own strengths and weaknesses, making them valuable for big data processing.ParquetFile('some_file.In this article, we will explore the key differences between Avro, Parquet, and ORC, shedding light on their characteristics, advantages, and typical use cases. What is the file format? The file format is one of the best ways to which information to stored either encoded or decoded data on the computer. ORC stands for Optimized Row Columnar (ORC) file format.
Exemple de code
import pyarrow. Compression on flattened Data works amazingly in ORC.In this article, we will check Apache Hive different file formats such as TextFile, SequenceFile, RCFile, AVRO, ORC and Parquet formats. Here’s what you’ll learn: Understand the need for efficient data storage methods as data continues to grow exponentially. Avro can be used outside of Hadoop, like in .Parquet format is designed for long-term storage, where Arrow is more intended for short term or ephemeral storage (Arrow may be more suitable for long-term storage after the 1. Converting your CSV data to Parquet’s columnar format and then compressing and dividing it will help you save a lot of money and also achieve better performance. Why analysts and engineers may prefer certain formats—and what “Avro,” “Parquet,” and “ORC” mean! CSV files are used for row storage, whereas Parquet files are used for column storage. Parquet is a Column based format. Environment setup.JSON: Ideal for data interchange between different systems and languages, especially over the web. If you want to retrieve the data as a whole you can use Avro. Parquet is more flexible, so engineers can use it in other architectures.