Map side join in hive
But first, let’s look at how . This is the old way of using map-side joins.
How Map-side join works in Hive?
For example, if one table has two buckets then the other table must have either 2 buckets or a . 2 min read · Jun 1, 2022 .Map-Side Join: Apache Hive Map Join is also known as Auto Map Join, or Map Side Join, or Broadcast Join. Bucketing has multiple .6M file size! 130 M rows; 3. In order to use a map-side join in Hive, the data being joined must be small enough to fit into the memory of the mapper task. One is to use the /*+ MAPJOIN()*/ hint just after the select keyword.
Hive Map-Side Joins: Plain, Bucket, Sort-Merge
For example the following piece of explain plan says that it is map-side join (Note Map Join Operator in the plan): Stage: Stage-33.Bucket-join: A bucket map join is used when the tables are large and all the tables used in the join are bucketed on the join columns.
Sort Merge Bucket Join in Hive
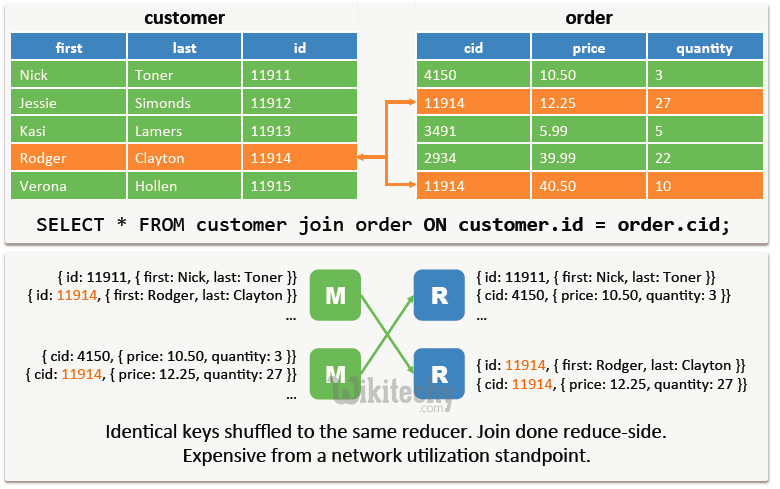
Small Table! Big Table! Join Condition! Average Map Join Execution time! Average New Optimized Map Join Execution time! Performance Improvement! 75 K rows; 383K file size! 130 M rows; 3. In Hive, Map-Join is a technique that materializes data for all tables involved in the join except for the largest table and then large table is streamed .table_name has to be the table that is smaller in size.comhadoop - about the Apache Hive Map side Join - Stack . Also during execution you can check logs on job tracker and see what mapper or reducer processes are doing.Map Side Join in Hive can be performed in two ways.Nous voudrions effectuer une description ici mais le site que vous consultez ne nous en laisse pas la possibilité. as common-join.By performing the join in the mapper, the amount of data that needs to be transferred between the mapper and reducer is reduced, resulting in improved performance. So that a join could be performed within a mapper without using a Map/Reduce step.val FROM a JOIN b ON (a.n_regionkey); Note that only .The first article in this series will talk about partitions, and the map side join feature.noconditionaltask = true; set hive. So the number of buckets depends on your table's size and the value of .
For all other keys, send it to a reducer which does the join. As is a size-of-data copy during the shuffle, it is slow. In Map-side Join a local MapReduce . Now run a set of mappers to read A and do the following: If it has key 1, then use the hashed version of B to compute the result. If the STREAMTABLE hint is omitted, Hive streams the rightmost table in the join.
Join Strategies in Hive
Load the smaller of the two tables into a hash table.There are two ways of using map-side joins in Hive.
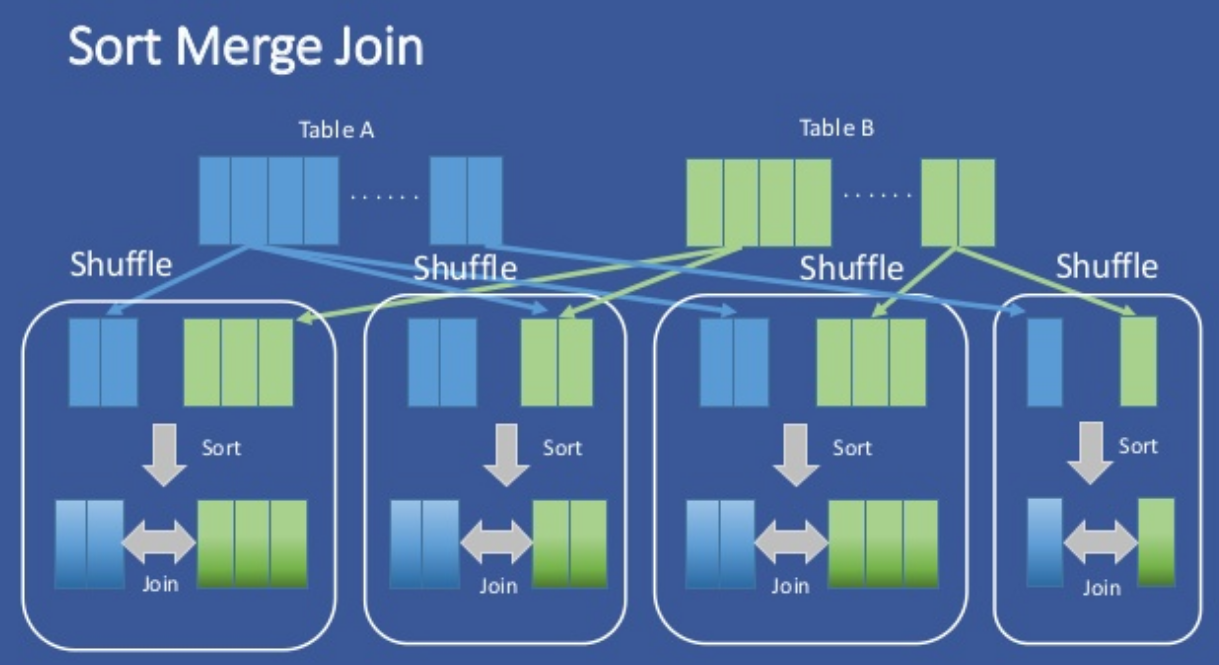
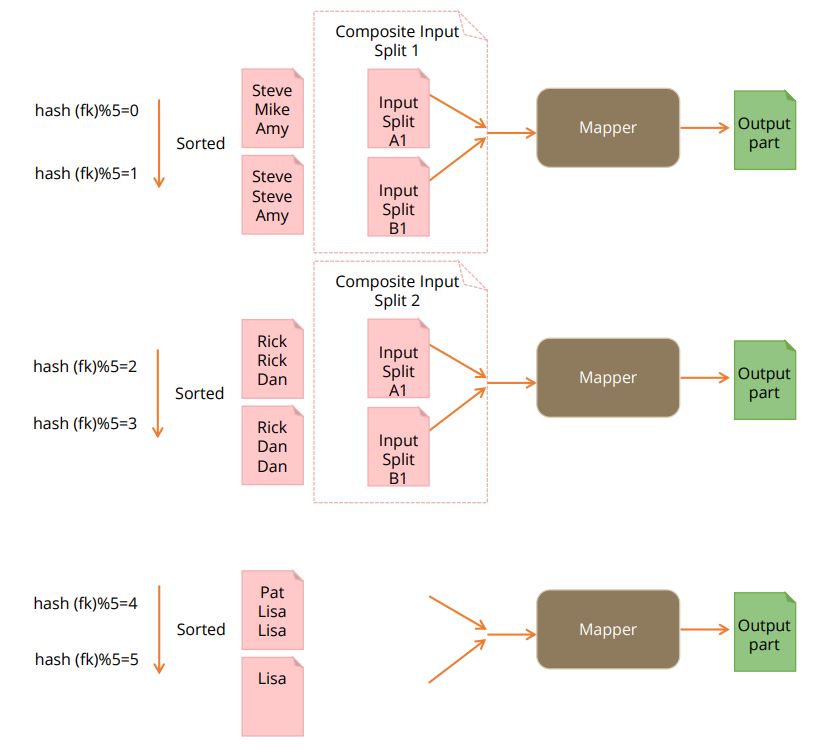
This article will help you increase the Hive-query optimization using bucket map join.join=true; set hive. Also, we use it to combine rows from .
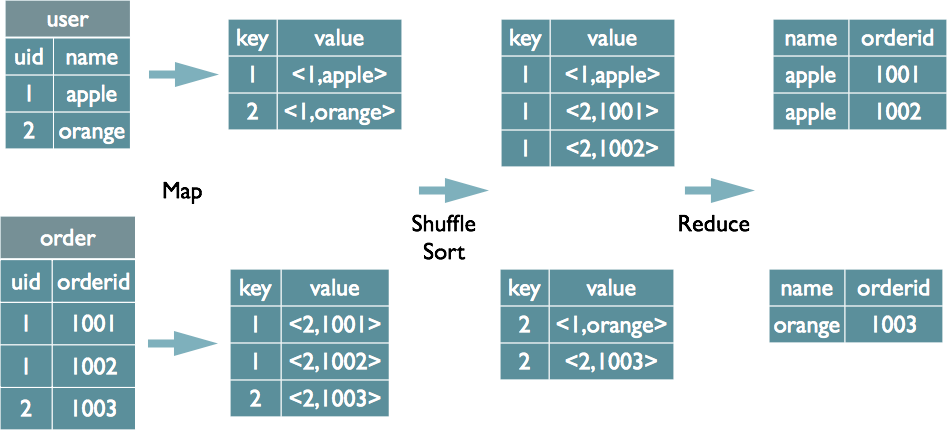
In this process, the entire mapreduce task of joins is executed in the map-phase itself.Executing map side joins in Hive Map side joins are special types of optimizations; Hive executes these automatically based on table sizes.Other names of Apache Hive Map Join are Auto Map Join, or Map Side Join, or Broadcast Join.Bucket Map Join---------------------------------In Apache Hive, while the tables are large and all the tables used in the join are bucketed on the join colum. In this blog we shall discuss about Map-side join and its advantages over the normal join operation in Hive. I am under the assumption that both map and reduce tasks are involved in SMB while only map tasks are involved in SMBM. If we want to perform a join query using map-join then we have to specify a keyword “/*+ MAPJOIN .size = 10000000; The first two settings will allow .I found we have to set the below property if want to run only map phase in join.comRecommandé pour vous en fonction de ce qui est populaire • Avis
Map Join in Hive
Bucketed Join: One can use bucketing feature in hive to store the data.We can improve this further by trying to reduce the processing of skewed keys. Basically, for combining specific fields from two tables by using values common to each one we use Hive JOIN clause. Map Side Join in HIVE. See JoinOperator. Then for each row retrieved from a, the join is computed with the buffered rows. This works if you have only one big table . However, there are much more to learn about Sort merge Bucket Map join in Hive.noconditionaltask.key1) JOIN c ON (c. and check the plan.5G file size! 1 join key, 2 join value! 3991 . After reading, it will serialize the in-memory hashtable into files on disk and compress the hashtable file into a tar file. The INNER JOIN keyword selects records with matching values in both tables. In this recipe, we are going to explore map side joins in further detail.
MapJoinOptimization
The smaller of the two .The Hive Metastore (HMS) is a central repository of metadata for Hive tables and partitions in a relational database, and provides clients (including Hive, Impala and Spark) access .Bucket Map Join in Hive. Partitions in Hive allow you to store relatable information together in the same .The following are the steps Hive will take to perform a join between these tables using the Map Side join feature. The 'default' join would be the shuffle join, aka.filesize (default is 25MB).Another (better, in my opinion) way to turn on mapjoins is to let Hive do it automatically. Apache Hive Map Join is also known as Auto Map Join, or Map Side Join, or Broadcast Join. In a map-side join, the join operation is .They are particularly useful when you need to aggregate data from different tables into a single comprehensive data set.
LanguageManual Joins
It relies on M/R shuffle to partition the data and the join is done on the Reduce side.Getting Involved With The Apache Hive Community.hadoop - about the Apache Hive Map side Join24 oct. Bucketing is different from Partitioning.
Understanding Map join in Hive
Right Outer Join.bucketmapjoin = true set hive.
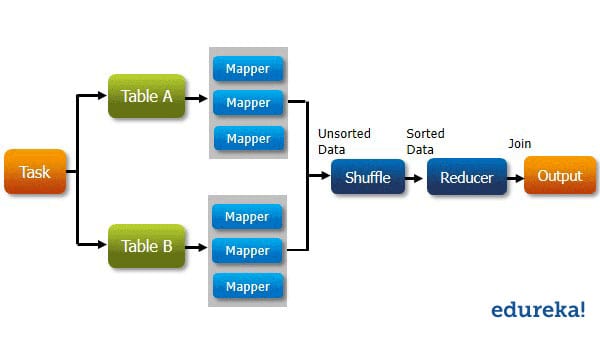
n_regionkey = b.This explanation is for Hive 0.
Map-Side Joins in Hive
since one of the tables in the join is a small table and can be loaded into memory, Hive Map Side Join is used.Then we perform a Hive Sort merge Bucket join feature.Map-Side Join Vs.if i set the property as false map .Learn how to perform map-side joins in Hive, a process where joins between two tables are performed in the map phase without the involvement of reduce .
Configuring Map Join Options in Hive
Mapjoins have a limitation in that the same table or alias cannot be . Use explain select . In other words, to combine records from two or more tables in the database we use JOIN clause.All five tables are joined in a single map/reduce job and the values for a particular value of the key for tables b, c,d, and e are buffered in the memory in the reducers. By setting the following property to true.
optimization
Full Outer Join.
Skewed Join Optimization
Apache Hive is an open source project run by volunteers at the Apache Software Foundation. table_name has to be the . The other way of using a map-side join is to set the following property to true and then run a join query:
Quora
default value: true.
Apache Hive Cookbook
In the last article, we discuss Map Side Join in Hive. Left Outer Join.Map join in hive.Differentiate between Map Side join and Reduce sid. during this type of join, one table should have buckets in multiples of the number of buckets in another table.Hive converts joins over multiple tables into a single map/reduce job if for every table the same column is used in the join clauses e.join, Hive generates three or more map-side joins with an assumption that all tables are of smaller size. AFAICT, bucketed map join doesn't take effect for auto converted map joins. In this recipe, we are going to explore .The syntax for Map Join in Hive. This controls whether hive should enable the optimization of converting common join into map-join based on the input file size or not. Please check this blog for more info link. A much better option is the MapJoin, see MapJoinOpertator.

join to true in your config, and Hive will automatically use mapjoins for any tables smaller than hive.Else should the below hints be included as well.Before that let’s understand why we need Map Side join? When we join two table in HIVE behind the scene internally it’s nothing but Map-Reduce, in that scenario Reducer has to do lot of works compare.You can see the updated Hivemapper Network Beta region boundaries for yourself in this interactive map: https://bit. It explains what exactly map and reduce will do. we use Hive Map Side Join when one of the tables in the join is a small table and can be loaded into memory.1、原理: 之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。但 Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小 . In this blog, we shall discuss about Map side join and its advantages over the normal join operation in Hive. First read B and store the rows with key 1 in an in-memory hash table.The Optimized Map Join. You will need to explicitly call out map join in the syntax like this: set hive.key1) is converted into a single map/reduce job as only key1 column for b is involved in the join. There are four types of joins available in Hive: Inner Join. Basically, while the tables are large and all the tables used in the join are bucketed on the join columns we use a Bucket Map .5G file size;! 1 join key, 2 join value! 1032 sec! 79 sec! 500 K rows; 2.But before knowing about this, we should first understand the concept of‘Join’ and what happens internally when we perform the join in Hive.bucketmapjoin = true; explain extended select /* +MAPJOIN(b) */ count(*) from nation_b1 a join nation_b2 b on (a. By Mahesh Golusu - March 16, 2021. Previously it was a subproject of . The basic idea is to create a new task, MapReduce Local Task, before the original Join Map/Reduce Task.Map side joins are special types of optimizations; Hive executes these automatically based on table sizes.