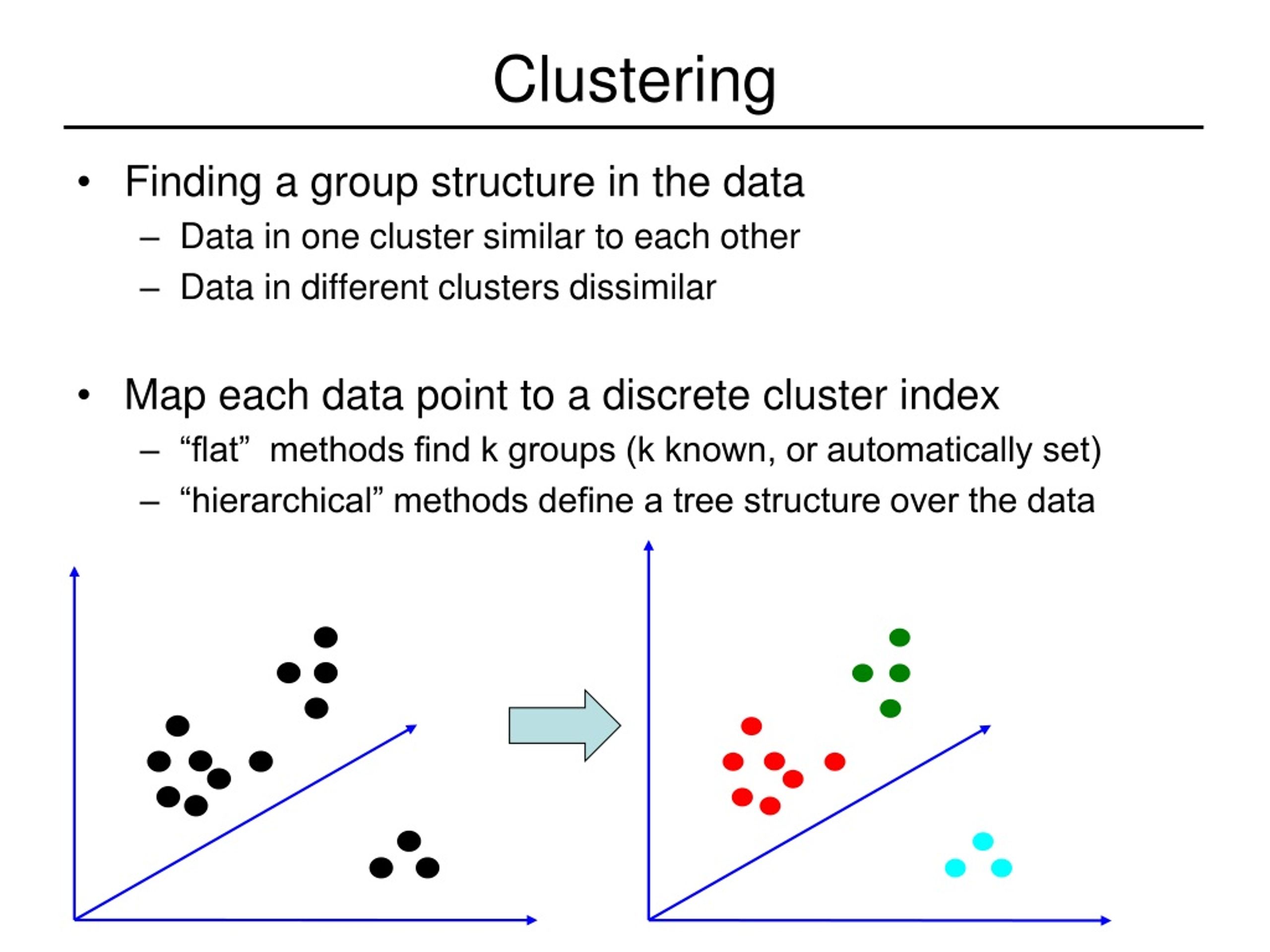
Clustering data points
Spectral Clustering: This type of clustering is based on graph theory and it tries to cluster the data by using the eigenvectors of the similarity matrix of the data points.
Complete Guide to Clustering Techniques
image segmentation. init{‘k-means++’, ‘random’}, callable or array-like of shape (n_clusters, n_features), default=’k-means++’. In this example, I am going to use the make_blobs the command to generate isotropic gaussian blobs which . These unsupervised learning, exploratory data analysis .
The complete guide to clustering analysis
In this article we’ll explore the core of the .Clustering is an unsupervised problem of finding natural groups in the feature space of input data. ISVs often face challenges in managing data for multiple tenants in a secure manner while keeping costs low. Each type of clustering method has its own strengths and limitations . Let the data points X = {x1, x2, x3, . The clusters are likely not the mean after the distribution as they only represent the .
Clustering by Passing Messages Between Data Points
It is based on the idea that a cluster is a high-density area that is surrounded by low-density regions. If one or more of the users show up in high proportion in the .
Finding and Visualizing Clusters of Geospatial Data
Clustering has . Cluster analysis is a type of unsupervised machine learning technique, often used as a preliminary step in all types of analysis.
10 Clustering Algorithms With Python
What Is Cluster Analysis?
Matthew Urwin | Oct 17, 2022.
2), the features with the highest variance proline and magnesium dominate the direction, which leads to a noisy clustering of the data points.
Clustering algorithms play an important role in data analysis.DBSCAN is a clustering solution for non-linear data points. Inertia is the sum of squared . In this article, we will explore one of the best alternatives for KMeans clustering, called the Gaussian Mixture Model. Step 1: Data Preparation.Fabric Multi-Tenant Architecture.Clustering is a technique in machine learning and data analysis that involves grouping similar data points based on certain features or.by Matilda Sarah.Explications and Illustration over 3D point cloud data. While you can see in the scaled case (second row in fig. See all Data + Analytics jobs in Boston.Clustering data by identifying a subset of representative examples is important for processing sensory signals and detecting patterns in data. Many clustering algorithms are available in Scikit-Learn and elsewhere, but perhaps the simplest to understand is an algorithm known as k-means clustering, which is implemented in sklearn.Iliya Valchanov 1 Feb 2023 6 min read. The “mean” refers to how a cluster should be the mean of the data points it represents. It involves using algorithms to group data points . But one key disadvantage is its sensitivity to outliers. Common FAQs on clustering. There are many different clustering algorithms and no single best .Clustering is a type of unsupervised machine learning that involves identifying groups within data, where each of the data points within the groups is similar (or related) and different (or unrelated) to data points in other groups.Dendrogram with data points on the x-axis and cluster distance on the y-axis (Image by Author) However, like a regular family tree, a dendrogram need not branch out at regular intervals from top to bottom as the vertical direction (y-axis) in it represents the distance between clusters in some metric.As you keep going down in a path, you keep . Here we will focus on two common methods: hierarchical clustering 2, which . Ces k points représentent alors les k classes dans cette première étape.Clustering is an unsupervised technique in which the set of similar data points is grouped together to form a cluster.It’s used to group the data points into k number of clusters based on their similarity. Cluster Analysis is a useful tool used to identify patterns and relationships within complex datasets. What is Clustering? Each clustering algorithm comes in two variants: a class, that . In our case, the Gini coefficient would measure if any of the users shows up in high proportion in either of the clusters that were created. Features with and without scaling and their influence on PCA.Using Gaussian Mixture Models (GMMs), we group data points into clusters based on their probabilistic assignments to various Gaussian components. Intuitively, these segments group similar observations together. When working with geospatial data, it is often useful to find clusters of latitude and longitude . medical imaging.Clustering (ou partitionnement des données) : Cette méthode de classification non supervisée rassemble un ensemble d’algorithmes d’apprentissage dont le but est de . Data points belonging to the same cluster exhibit similar features, whereas data points from different clusters are dissimilar to each other. Meaning each data point is assigned to a single cluster.A cluster is a group of data points that are similar to each other based on their relation to surrounding data points. search result grouping.It's a hard clustering method.Temps de Lecture Estimé: 10 min
The Ultimate Guide to Clustering Algorithms and Topic Modeling
In the process of Mean-shift, firstly, the mean of the offset of the current data point is calculated, then, the .The task of grouping data points based on their similarity with each other is called Clustering or Cluster Analysis. Bottom-up algorithms regard data points as a single cluster until agglomeration units clustered pairs into a single cluster of data points. After clustering, each . La méthode centroïde la plus classique est la méthode des k-moyennes. This method is defined under the branch of .
What is Clustering?
12 min read · Feb 8, 2024 . It starts by exploring the small area if . The greater the similarity (or homogeneity) within a group and the more significant the difference between groups . Density-based clustering deals with the density of the data points. K-means is easy to implement and interpret. A point to note is that each linkage . anomaly detection. Distortion is the average of the euclidean squared distance from the centroid of the respective clusters. However, this is not useful. Let’s recall the flowchart for Gaussian Mixture Models: We’ll follow these steps to implement Gaussian Mixture Models. A dendrogram or tree of network .
Clustering Data Mining Techniques: 5 Critical Algorithms 2024
Clustering algorithms allow data to be partitioned into subgroups, or clusters, in an unsupervised manner. Due to these limitations, we should know alternatives for KMeans when working on our machine learning projects.The within cluster variance is calculated by determining the center point of the cluster and the distance of the observations from the center. Two values are of importance here — distortion and inertia.Clustering has primarily been used as an analytical technique to group unlabeled data for extracting meaningful information.
Introduction to Embedding, Clustering, and Similarity
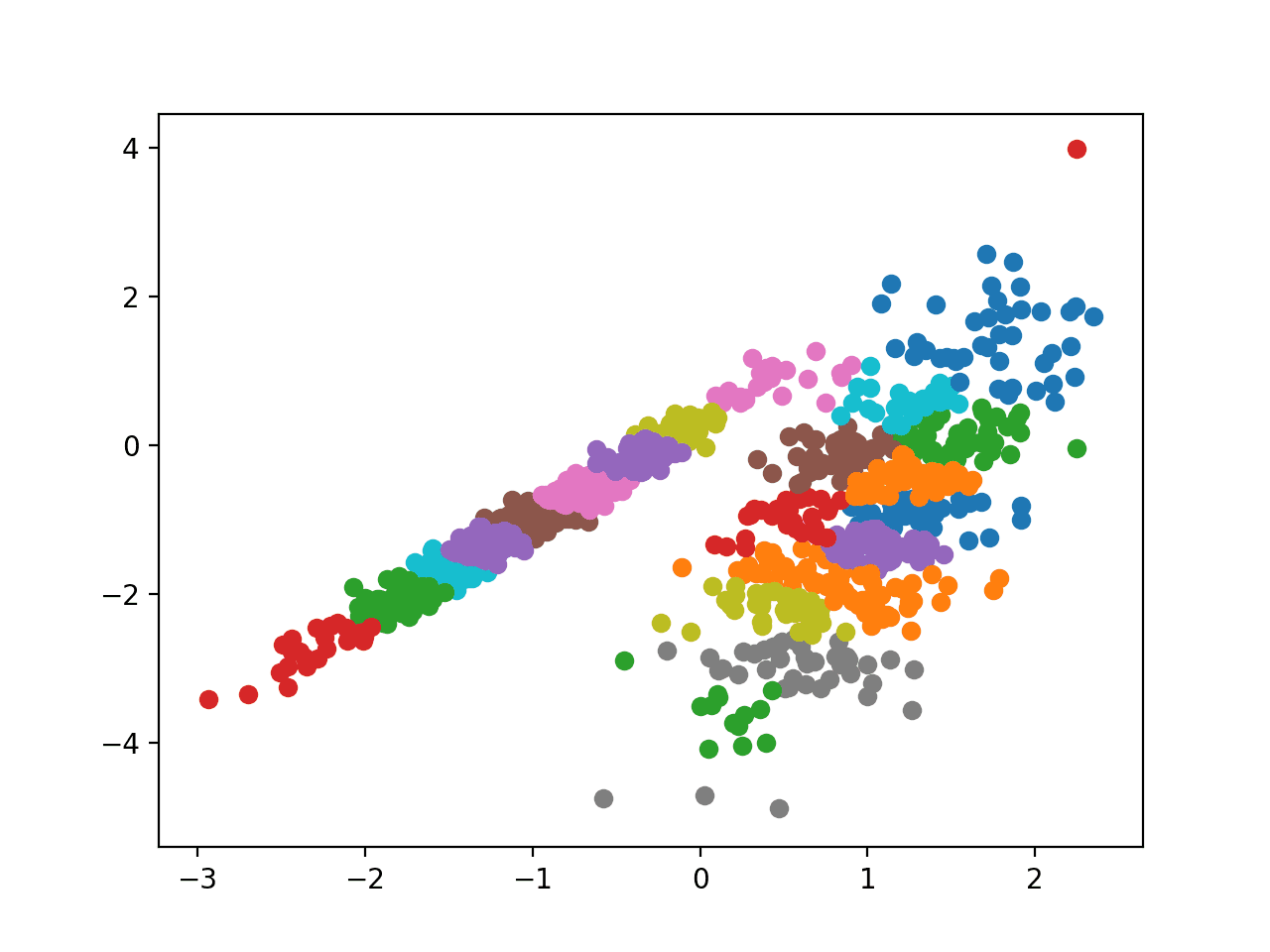
2— A scatter plot of the example data with different clusters denoted by different colors.
GMMs for Clustering
Therefore, we want to increase k, but only to a point where the drop in SSE on further increment is marginal —.5 essential clustering algorithms. Clustering is a type of unsupervised learning that groups similar data points together based on certain criteria.As mentioned earlier, the cluster label assignment was based on picking the highest probability of a specific data point belonging to a specific cluster.market segmentation.
GMM: Gaussian Mixture Models
Find out who's hiring in Boston.
Clustering Algorithms
While trying to merge two clusters, the variance is found between the clusters and the clusters are merged whose variance is less compared to the other combination. The different types of clustering methods include Density-based, Distribution-based, Grid-based, Connectivity-based, and Partitioning clustering. View 2885 Jobs Density-Based Clustering. On initialise .
Clustering Techniques
Hierarchical clustering is more informative than K-Means but it suffers from a similar weakness of being sensitive to extreme . There are two types of Clustering Algorithms: Bottom-up and Top-down. Many clustering algorithms are available in . Let's quickly look at types of clustering algorithms and when you should choose each type.Towards Data Science. k-Means is one of the popular partition clustering techniques, where the data is partitioned into k unique clusters.


Data points belong to the cluster with the nearest mean or cluster point. Method for initialization:
Cluster Analysis
OPTICS [25] is an improvement of ε-neighborhood, and it overcomes the shortcoming of ε-neighborhood such as being sensitive to two parameters, the radius of the neighborhood, and the minimum number of points in a neighborhood.La méthode centroïde la plus classique est la méthode des k-moyennes.For K total labels, the Gini coefficient for each cluster is given as follows, where p is the proportion of data point with label i in the cluster. Let’s see a simple example of how K-Means clustering can be used to segregate the dataset. Euclidean distance is used to calculate the similarity. It is useful when the data points have non-convex shapes. The clusters are tied to a threshold — a given number that indicates the . In this article, using Data Science and Python, I will show how different Clustering algorithms . Photo by Rod Long on Unsplash. A Cluster is said to be good if the intra . It is a main task of exploratory data analysis and is . In the unscaled case (first row in fig. k-Means clustering.Critiques : 147Clustering Algorithms.
On initialise l’algorithme avec k points au hasard parmi les n individus.Cluster analysis, also known as clustering, is a statistical technique used in machine learning and data mining that involves the grouping of objects or points in such a way that objects in the same group, also known as a cluster, are more similar to each other than to those in other groups.You can think of clustering as putting unorganized data points into different categories so that you can learn more about the structures of your data.Clustering algorithms seek to learn, from the properties of the data, an optimal division or discrete labeling of groups of points.
Introduction To Clustering Algorithms
However, that does not mean that the point is definitely part of that cluster (distribution).
How to Cluster Data!
Clustering
How to Form Clusters in Python: Data Clustering Methods
5 — Calculate which cluster each of the data-points is closest to. What Is Clustering? Clustering is the process of separating different parts of data based on common characteristics. Y axis=sum of SSE across clusters. We review data clustering, intending to underscore .2), the magnitudes are about the .