Neural network gradient descent formula
# Principe
What is Gradient Descent?
μ ( greek letter mu )= all data points. It works by iteratively .Gradient Descent.It also provides the basis for many extensions and modifications that can result in better performance.Gradient Descent has been doing a fairly good job in helping with these two necessities.The process of gradient descent is very formulaic, in that it takes the entirety of a dataset's forward pass and cost calculations into account in total, after which a wholesale propagation of errors backward through the network to neurons is made. Part 3: The Role of Learning Rate in Optimization.Gradient is a commonly used term in optimization and machine learning.
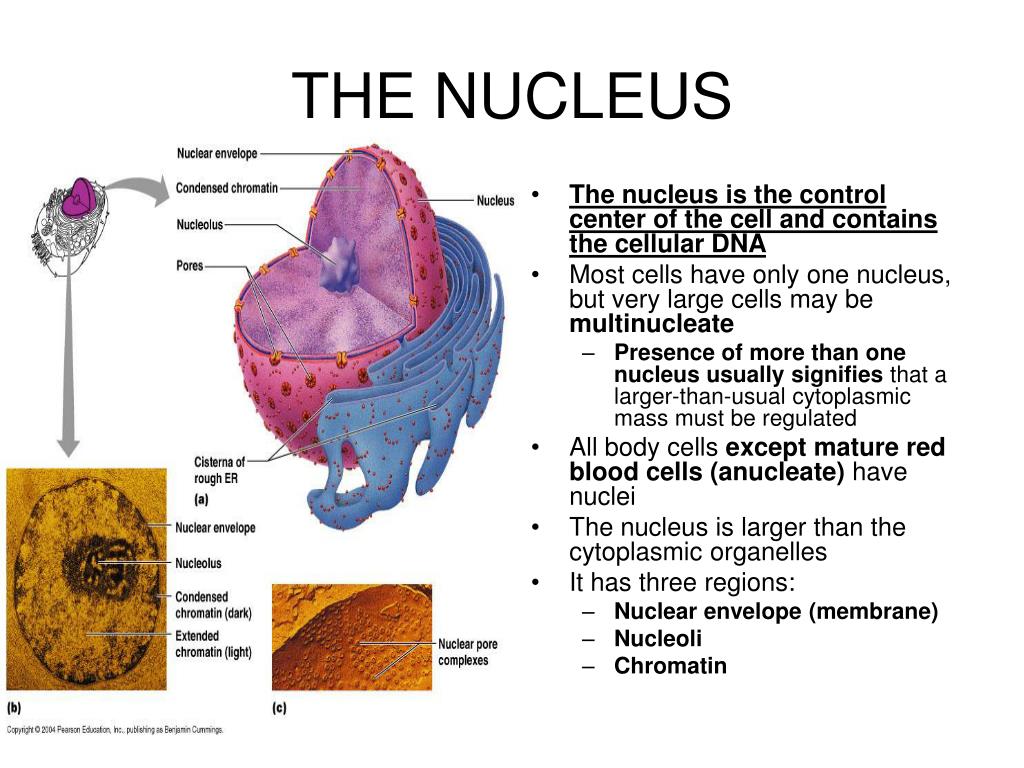
Finding the Cost Function of Neural Networks
Stochastic Gradient Descent — Clearly Explained !! Aishwarya V Srinivasan · . It does this by taking a guess x 0.
Gradient descent
Part 3: Hidden layers trained by backpropagation. Improve this question.Gradient descent minimizes differentiable functions that output a number and have any amount of input variables. Now, let’s talk about how the network learns by seeing many labeled training data. B0 and B1 are also called coefficients. Here’s the MSE equation, where C is our loss function (also known as the cost function ), N is the number of training images, y is a vector of true labels ( y = [ target (x ₁ ), target (x ₂ ).
Gradient Descent From Scratch
gradient-descent. Use the mean gradient we calculated in step 3 to update the weights. In this article, I have tried my. Suppose we have a function f : Rn ! Rm that maps a vector of length n to a vector of length m: f(x) = [f1(x1; :::; .Single-Layer Neural Networks and Gradient Descent. Part 4 of Step by Step: The Math Behind Neural Networks.Our findings are put in contrast to common wisdom on convergence properties of neural networks and dynamical systems theory.
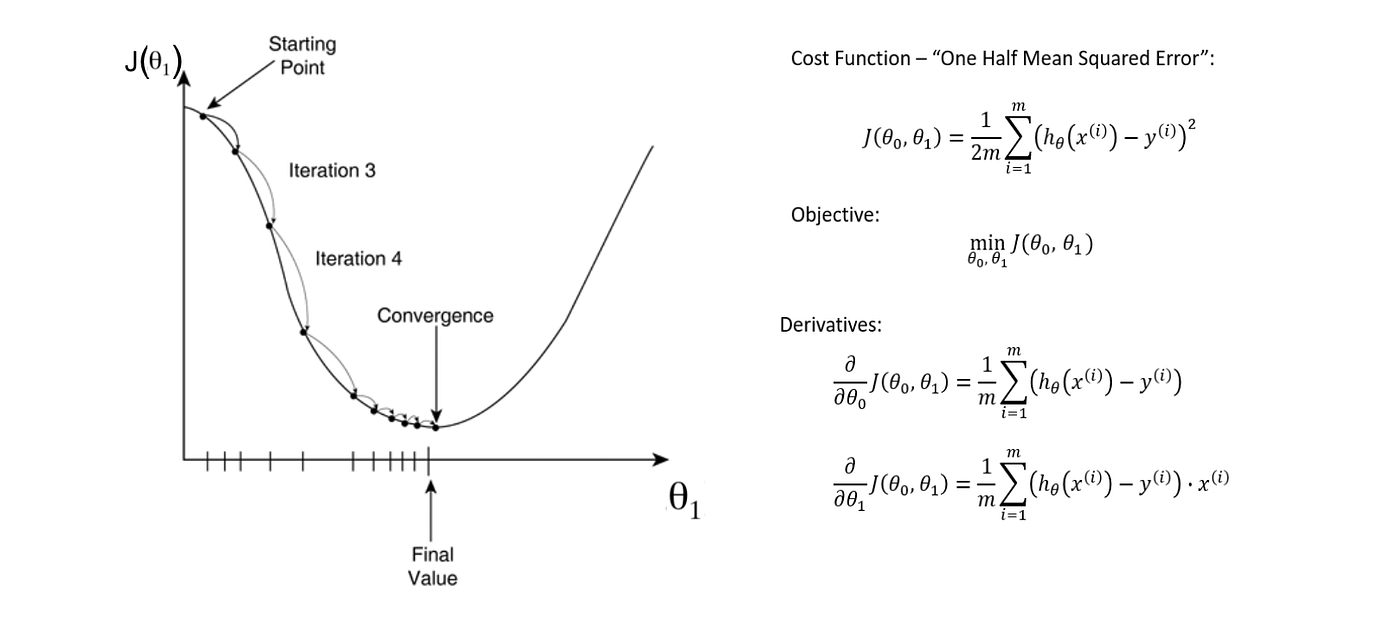
In the previous section, we showed how to run gradient descent for a simple linear regression problem, and declared that doing so is guaranteed to find the correct parameters. In this context, proper training of a neural network is the most important aspect of making a reliable model.Discover key deep learning optimization algorithms: Gradient Descent, SGD, Mini-batch, AdaGrad, and others along with their applications. How Gradient Descent helps is: Source: miro.Gradient descent, how neural networks learn. When implementing Gradient Descent in practice, we also . RSS Subscribe via Email. by Sebastian Raschka.
Gradient Descent, Step-by-Step
We do this by calculating 1) the gradient which gives us the direction of the slope and 2) calculating our step-size (i.
Gradient Descent — Neural Networks by Hand
5) is linear in µand νrespectively.MSE simply squares the difference between every network output and true label, and takes the average.Temps de Lecture Estimé: 5 minGradient Descent helps to find the degree to which a weight needs to be changed so that the model can eventually reach a point where it has the lowest loss. This is true for optimizing a linear model as we did, but it’s not true for neural networks, due to .Gradient Descent Algorithm iteratively calculates the next point using gradient at the current position, scales it (by a learning rate) and subtracts obtained value from the current position (makes a step). For example, if our dataset contains 10,000 samples, a suitable size of n would be 8,16,32, 64, 128.In brief, gradient descent is an optimization algorithm that we use to minimize loss function in the neural network by iteratively moving in the direction of the steepest descent of the function.Thus, gradient descent will result in negligible updates to the network and hence network training will cease.For the mini-batch gradient descent, we must divide our training set into batches of size n. Section 1- Gradient Descent for Neural Netowrks.Understanding Backpropagation With Gradient Descent.2: The ‘Stochastic’ in Stochastic Gradient Descent. Let's visualize the function first and then find its minimum value. It has been very helpful for me. This article offers a brief glimpse of the history and basic concepts of machine learning.This learning process can be described by the simple equation: W (t+1) = W (t) — dJ (W)/dW (t).Gradient descent is the same regardless of the general problem being solved by the network.
Computing the Gradient in an RNN
The basic building block of vectorized gradients is the Jacobian Matrix.
How to Implement Gradient Descent Optimization from Scratch
This training is usually associated with the term . They control how a . Called BPTT: Back Propagation .In this paper, we present a fast natural gradient descent (FNGD) method, which only requires computing the inverse during the first epoch.In this visualization, your goal is to recover the ground truth parameters used to generate a training set.The gradient descent weight update formula is a common optimization algorithm that can be used for various machine learning models, including neural networks, linear regression, logistic regression, and support vector machines. Analogous to the batch gradient descent we compute and average the gradients across the data instance in a mini-batch. @Goyo: solution (1) seems to be coherent with the math (partial . In order to understand what a gradient is, you need to understand what a . To solve complex problems, non-linear transformation is introduced to be achieved by an Activation function.comGradient Descent in Linear Regression - GeeksforGeeksgeeksforgeeks.
Gradient Descent in Python: Implementation and Theory
An example function that is often used for testing the performance of optimization algorithms on saddle points is the Rosenbrook function .orgRecommandé pour vous en fonction de ce qui est populaire • Avis
Gradient Descent Algorithm — a deep dive
Backpropagation is a key step in training a neural network model.

neural-network.
A Deeper Look into Gradient Based Learning for Neural Networks
Calculate the mean gradient of the mini-batch.
Understanding Backpropagation With Gradient Descent
Calculons le gradient de f ( x, y) : (3) ∇ f ( X) = ( d f d x d f d y) = ( 2 x − 4 4 y − 12) Les coordonnées seront itérativement mises à jour selon les formules suivantes : (4) x n + 1 = x n − α ( 2 x n − 4) (5) y n + 1 = y n − α .Gradient Descent Algorithm - Javatpointjavatpoint. ∑xδxl(axl 1)T = .y = f ( x) the gradient descent update is given by. This work also contributes . 9 min read · Mar 10, 2024--allglenn. For mini-batch gradient descent, the mini-batches are usually powers of two: 32 samples, 64, 128, 256, and so on.Since 1000 iterations are typical, the algorithm will require 100,000 * 1000 = 100 000 000 calculations to complete.3 Global Optimality and Convergence of the Mean-Field Limit In this section, we will introduce our main .neural network f(·;µ) and g(·;ν)) in (3. This process would result in the same errors and subsequent propagated errors each and every time it is undertaken.
Gradient Descent With Momentum from Scratch
In other words, we say that a minima is . In this post, I’m going to explain what is the Gradient Descent and how to . The function has a minimum value of zero at the origin. For example, deep learning neural networks are fit using stochastic gradient descent, and many standard optimization algorithms used to fit machine learning algorithms use gradient information.
Stochastic Gradient Descent — Clearly Explained
asked Aug 17, 2019 at 18:59.
Descente de gradient pour les réseaux de neurones
Repeat steps 1–4 for the mini-batches we created.Now that we have a general purpose implementation of gradient descent, let's run it on our example 2D function f (w1,w2) = w2 1 + w2 2 f ( w 1, w 2) = w 1 2 + w 2 2 with circular contours. Gradient descent is slow on large amounts of data because that . The term ‘stochastic’ refers to a . After a conceptual overview of what backpropagation aims to achieve, we go through a brief recap of the relevant concepts from calculus.
Computing Neural Network Gradients
Deep Learning Optimization Algorithms
We will take a look at the first algorithmically described neural network and the gradient descent algorithm in context of adaptive .Gradient Descent (GD) is a widely used optimization algorithm in machine learning and deep learning that minimises the cost function of a neural network model during training. Cost functions, Gradient Descent and . It’s usually quite complicated due to the large number of parameters and their arrangement in multiple layers. The output of linear . Firstly, we reformulate the gradient . In words, the formula says to take a small step in the direction of the negative gradient.Gradient Descent is the algorithm that facilitates the search of parameters values that minimize the cost function towards a local minimum or optimal accuracy. In this post, we develop a thorough understanding of the backpropagation algorithm and how it helps a neural network learn new information.This was the first part of a 4-part tutorial on how to implement neural networks from scratch in Python: Part 1: Gradient descent (this) Part 2: Classification. Stochastic Gradient Descent (SGD) adds a twist to the traditional gradient descent approach. Hector Alavro Rojas April 8, 2018 at 1:22 am # Thanks a lot for all your explanations, Jason., artificial neural networks) were introduced to the world of machine learning, applications of it have been booming. B0 is the intercept and B1 is the slope whereas x is the input value. Part 4: Vectorization of . This article is trying to explain all of them and how they all are trying to overcome limitations of their ancestors.They all are some variants of classical Gradient Descent Algorithm and ADAM which is a combination of RMSprop and momentum is considered to be current state of the art. j= output units of the network.Towards Data Science.
Single-Layer Neural Networks and Gradient Descent
Saddle point — simultaneously a local minimum and a local maximum.z = (input * weight) + bias. Using Gradient .Gradient descent is a first-orderiterative optimization algorithm for finding a local minimum of a differentiable function. In the last lesson we explored the structure of a neural network. Let’s consider a linear model, Y_pred= B0+B1 (x).
.png)
The core idea is a method known as gradient descent, which underlies not only how neural networks learn, but a lot of other machine learning . The algorithm also provides the basis for the widely used extension called stochastic gradient descent, used to train deep learning neural networks.The gradient vector calculation in a deep neural network is not trivial at all. where α is a learning rate hyperparameter and δ y δ x is the derivative of x with respect to y.Mastering Gradient Descent: Optimizing Neural Networks with Precision. Consider that all the .For Batch gradient descent, the batch size is the total number of samples in the training dataset.Gradient descent is an optimization algorithm that follows the negative gradient of an objective function in order to locate the minimum of the function. and successively applying the formula x n + 1 = x n − α ∇ f ( x n) . Any chance to get examples of how to apply Gradient Descent and Stochastic Gradient Descent using Artificial .
Calculating Gradient Descent Manually
Training a neural network involves determining the set of parameters \ (\mathbf {\theta} = \ {\mathbf {W},\mathbf {b}\}\) that reduces the amount errors that the .
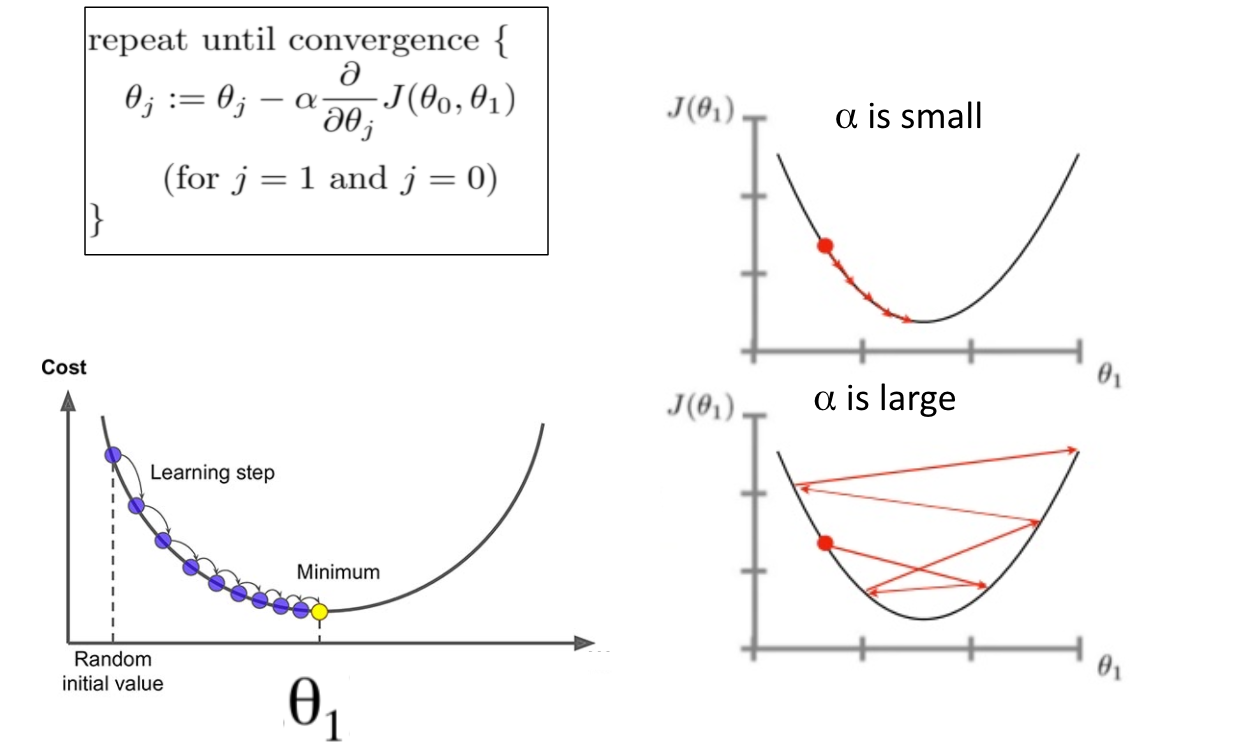
After computing the gradient estimate, we update the parameter along the .
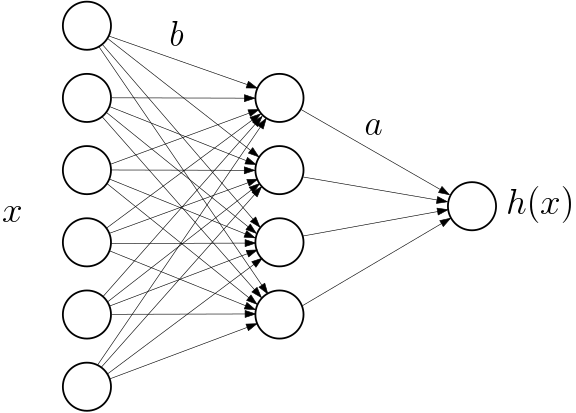
How to implement a neural network (1/5)
However, its applicability may depend on the specific problem and the nature of the model. You can fit a linear model \hat {y} = wx + b y =wx+b on the training set using gradient descent.In this paper, an adaptive gradient-enhanced physics-informed neural network method(A-gPINN) is proposed to investigate the dynamics of solitons in tapered .target (x 𝑛) ]), and o is a vector of . It trains machine learning models by minimizing errors between predicted and actual results.